


How Figma built DBProxy for sharding Postgres
 By Lukas Fittl
By Lukas FittlIn E106 of “5mins of Postgres” we discuss how Figma scaled out their Postgres installation by 100x over 4 years, and recently switched to horizontal sharding using their DBProxy query proxy. We also compare their approach to Notion’s sharding setup, as well as the Citus extension for Postgres.
Share this episode: Click here to share this episode on LinkedIn or on X/Twitter. Feel free to sign up for our newsletter and subscribe to our YouTube channel.
Transcript
We’ll start with this blog post by Sammy Steele, who leads the database team at Figma that has implemented this change. In the post she describes how they’ve scaled 100x over the last 4 years.
Reaching the biggest RDS instance, and what happened next
Back in 2020, they were running on AWS’ largest physical RDS instance. They had moved to an “r5.24xlarge”, if I recall correctly. And then by 2022, they essentially scaled out to a distributed architecture, where they split out different logical parts of the application, like files, organization, into different vertical partitions, each residing on a different database server. That helped them maintain the growth whilst the team was building this horizontal sharding solution.
Now, the motivation for going to a horizontal sharded setup is that some of their tables contain several terabytes of data and billions of rows.
And that became a problem on a single database server because they kept seeing issues with Postgres VACUUM, keeping up on a very large table. They had a lot of I/Os that exceeded the IOPS that AWS could support on a single database server. And so they couldn’t essentially solve this anymore because the single table of the same data was too large.
Why not a “distributed” database?
Now, of course, sometimes people bring up why are you not using CockroachDB or Yugabyte, or Spanner or other distributed databases. And I think one of the main motivations that they had here is, they wanted to stay on what they know works well, which is RDS Postgres.
And they didn’t want to have a big migration. So the big risk here of course, is if you move a huge database like they have, things go wrong, data is expensive to move. It’s hard to do well. And even though, performance might look good for a certain workload you’re testing, the tail latencies are sometimes harder to assess.
And so they knew how to manage Postgres. It just had too much data as a whole.
And so I’m actually a big subscriber to not unnecessarily switching databases. If you can make Postgres work because these days we have enough tooling around Postgres that we can scale Postgres way beyond what was possible previously.
Challenges when sharding Postgres
Now, they did identify a couple of challenges that I think some of them are still working on, but for example, certain SQL queries become inefficient or impossible to support. So sometimes, SQL queries are complicated, they access data across multiple users for example. And so these things need special care.
You of course also need to make sure your application code can route to the correct shards correctly. And if you make schema changes, you must coordinate them across all your shards. Also, transactions can span multiple shards. Postgres has two-phase transactions to help with this, but you do need to orchestrate them. And so if you have multiple Postgres servers that are trying to commit the same transaction, you’ll have to think about how to make sure your application is consistent.
DBProxy - Postgres sharding via a query proxy
The biggest thing that I think they’ve done differently from what I’ve seen other people do is that they’ve actually built a proxy to handle SQL queries that are generated in the application layer, and then dynamically route the queries to the Postgres databases.
You can see the application layer talks to the DB proxy, proxy then talks to PgBouncer and then PgBouncer sits in front of each of these database servers.
Parsing and planning distributed Potsgres queries
Now, my understanding is the DBProxy component they built here is currently not open source, it’s tailored to their workloads also, but the idea is that they essentially read the SQL queries that are coming in, they then evaluate the query, and extract which logical shard IDs they need to access based on that query’s table references, and then they have a planner that maps those logical IDs to the physical database servers they needed to connect to, and then it also rewrites the queries to execute on the appropriate shards.
They give an example of a simple case where you’re querying for a particular shard key, in this case “X”, this shard key “X” maps to a single logical shard ID, and then they identify which physical server that shard ID is located on, so in this case shard 4. The idea is that if they’re rebalancing the servers, if they’re moving around data, they need to make sure that their DBProxy is aware of the topology changes.
Scatter-gather queries
Now, they’ve also implemented basic support for what they call “scatter-gather” queries. Now, these are queries that would get the data from multiple shards. The best example is you’re doing “SELECT * FROM table”, but you’re not including the shard key explicitly. And so the DBProxy in this case has to go across all of them and get the data. Obviously, this has a lot of complexity to it. And I imagine that this is really where if you were to build this yourself and you had a workload where you’re doing a lot of cross shard queries, this is really hard to get right.
Validating application compatibility ahead of time
Now, they did one more thing here, which I found an interesting technique. Which is when the started rolling this out, they wanted to first validate that they’re not making assumptions incorrectly. And so what they ended up doing is they ended up using views on their original database to validate that they were able to query data independently.
So, what they did is they created a view and that view would imitate the sharding setup they had. They hashed the shard key, and then they were saying, okay, this view only has the data of this hash function on the shard key from the minimum to the maximum range. And that way, by creating these views on the existing unsharded physical database, they were able to validate that the application didn’t break when they moved to this new model.
They went live with their first sharded tables in September 2023 and it would say well done to the team at Figma for making all of this work.
Comparing sharding approaches
Now, I tried to do a quick illustration of how these setups compare. On the left side, you see Figma’s setup, on the middle you see Notion, and on the right side you see Citus:
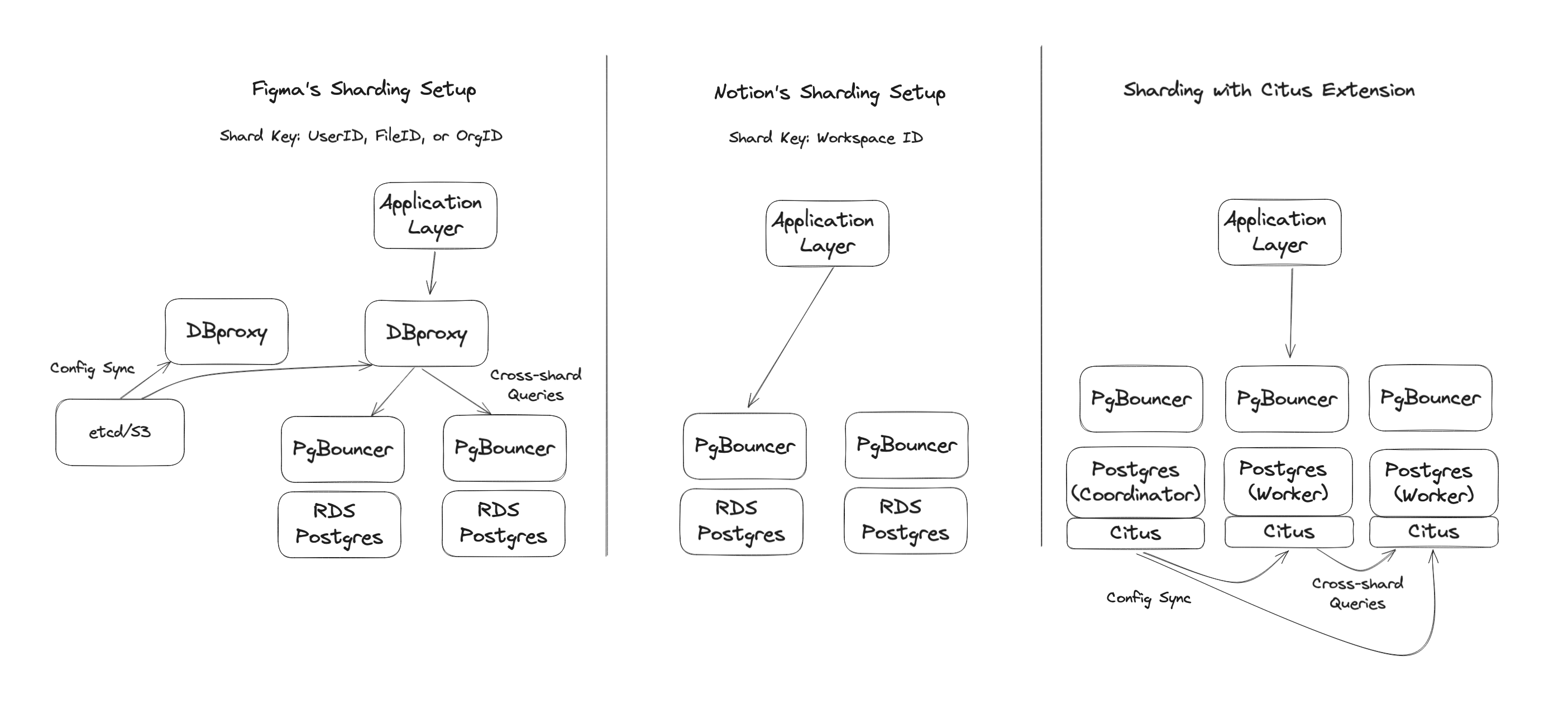
Figma’s sharding through proxy
On the left side, what Figma is doing is they have the application layer, application layer talks to the DBProxy, DBProxy talks to PgBouncer, which sits in front of the database server, and then the database server executes the queries. If you have cross-shard queries, the DBProxy is responsible for making those cross-shard queries work.
Figma is sharding on different keys. Sometimes they use a user ID, sometimes a file ID or sometimes organization ID. So they essentially said, we have different use cases here, and so we don’t want to shard just by one customer ID, for example.
Notion’s sharding through application logic
And then, Notion’s sharding setup in a sense is a bit simpler. We talked previously about the original blog post, where they described their sharding setup. And then earlier last year, they released an updated post where they talked about how they have increased capacity.
They are, in my understanding, sharding mainly by Workspace ID, as they described in their blog posts. The application layer has the awareness of where to route the queries, that goes to a PgBouncer, and then ultimately also to an RDS Postgres. If they have cross-shard activity, they presumably pull back that data onto the application, and then the application can do the merge.
Citus extension for sharding directly in Postgres
The Citus extension for Postgres has been around for many years. The one thing I’ll say about Citus is that, first of all it’s open source, so you could just start using it today without having to build your own. What happens is your application layer does talk to the database server, Postgres has the Citus extension, so if the query is on a distributed table in Postgres, then the Citus query planner gets active.
Citus is also able to do cross-shard queries and I would argue it’s probably the most sophisticated of the three setups here, in terms of being able to do complex cross-shard queries, as well as two-phase transactions.
In conclusion
If you don’t have your own dedicated team, but you do need to scale out Postgres, I would seriously consider the Citus extension for Postgres as a starting point. If you’re at Figma’s scale and want to (or need to) build your own, take a look at their approach, or read up on how Notion designed their sharding setup.
I hope you learned something new from E106 of 5mins of Postgres. Feel free to subscribe to our YouTube channel, sign up for our newsletter or follow us on LinkedIn and X/Twitter to get updates about new episodes!