
The Unexpected Find That Freed 20GB of Unused Index Space
 By Haki Benita
By Haki BenitaHow to free space without dropping indexes or deleting data
At pganalyze, we’ve been a fan of Haki Benita’s writing for quite some time. This article back from February 2021 is worth a read. Haki kindly gave us permission to republish his post on the pganalyze blog so you could benefit from it. Haki is a software developer and a technical lead who takes special interest in databases, web development, software design and performance tuning. You can find the original article on his blog at hakibenita.com.
Every few months we get an alert from our database monitoring to warn us that we are about to run out of space. Usually we just provision more storage and forget about it, but this time we were under quarantine, and the system in question was under less load than usual. We thought this is a good opportunity to do some cleanups that would otherwise be much more challenging.
To start from the end, we ended up freeing more than 70GB of un-optimized and un-utilized space without dropping a single index or deleting any data!
Using conventional technics such as rebuilding indexes and tables we cleared up a lot of space, but then one surprising find helped us clear an additional ~20GB of unused indexed values!
This is what the free storage chart of one of our databases looked like in the process:
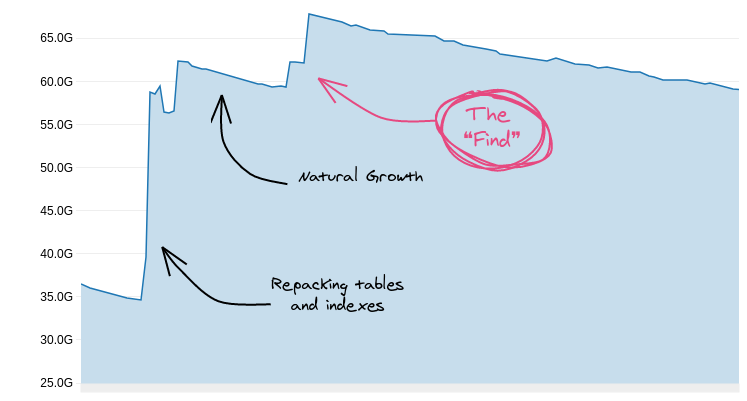 Free space over time (higher means more free space)
Free space over time (higher means more free space)
The Usual Suspects
Provisioning storage is something we do from time to time, but before we throw money at the problem we like to make sure we make good use of the storage we already have. To do that, we start with the usual suspects.
Unused Indexes
Unused indexes are double-edged swords; you create them to make things faster, but they end up taking space and slow inserts and updates. Unused indexes are the first thing we always check when we need to clear up storage.
To find unused indexes we use the following query:
SELECT
relname,
indexrelname,
idx_scan,
idx_tup_read,
idx_tup_fetch,
pg_size_pretty(pg_relation_size(indexrelname::regclass)) as size
FROM
pg_stat_all_indexes
WHERE
schemaname = 'public'
AND indexrelname NOT LIKE 'pg_toast_%'
AND idx_scan = 0
AND idx_tup_read = 0
AND idx_tup_fetch = 0
ORDER BY
pg_relation_size(indexrelname::regclass) DESC;
The query is looking for indexes that were not scanned or fetched since the last time the statistics were reset.
Some indexes may seem like they were not used but they were in-fact used:
-
The documentation lists a few scenarios when this is possible. For example, when the optimizer uses meta data from the index, but not the index itself.
-
Indexes used to enforce unique or primary key constraints for tables that were not updated in a while. The indexes will look like they were not used, but it doesn’t mean we can dispose of them.
The find the unused indexes you can actually drop, you usually have to go over the list one by one and make a decision. This can be time consuming in the first couple of times, but after you get rid of most unused indexes it becomes easier.
It’s also a good idea to reset the statistics counters from time to time, usually right after you finished inspecting the list. PostgreSQL provides a few functions to reset statistics at different levels. When we find an index we suspect is not being used, or when we add new indexes in place of old ones, we usually reset the counters for the table and wait for a while:
-- Find table oid by name
SELECT oid FROM pg_class c WHERE relname = 'table_name';
-- Reset counts for all indexes of table
SELECT pg_stat_reset_single_table_counters(14662536);
We do this every once in a while, so in our case there were no unused indexes to drop.
Index and Table Bloat
The next suspect is bloat. When you update rows in a table, PostgreSQL marks the tuple as dead and adds the updated tuple in the next available space. This process creates what’s called “bloat”, which can cause tables to consume more space than they really need. Bloat also affects indexes, so to free up space, bloat is a good place to look.
Estimating bloat in tables and indexes is apparently not a simple task. Lucky for us, some good people on the world wide web already did the hard work and wrote queries to estimate table bloat and index bloat. After running these queries you will most likely find _some** bloat, so the next thing to do it clear up that space.
Clearing Bloat in Indexes
To clear bloat in an index, you need to rebuild it. There are several ways to rebuild an index:
- Re-create the index: If you re-create the index, it will be built in an optimal way.
- Rebuild the index: Instead of dropping and creating the index yourself, PostgreSQL provides a way to re-build an existing index in-place using the REINDEX command:
REINDEX INDEX index_name;
- Rebuild the index concurrently: The previous methods will obtain a lock on the table and prevent it from being changed while the operation is in progress, which is usually unacceptable. To rebuild the index without locking it for updates, you can rebuild the index concurrently:
REINDEX INDEX CONCURRENTLY index_name;
When using REINDEX CONCURRENTLY, PostgreSQL creates a new index with a name suffixed with _ccnew, and syncs any changes made to the table in the meantime. When the rebuild is done, it will switch the old index with the new index, and drop the old one.
 Clearing bloat in Indexes
Clearing bloat in Indexes
If for some reason you had to stop the rebuild in the middle, the new index will not be dropped. Instead, it will be left in an invalid state and consume space. To identify invalid indexes that were created during REINDEX, we use the following query:
-- Identify invalid indexes that were created during index rebuild
SELECT
c.relname as index_name,
pg_size_pretty(pg_relation_size(c.oid))
FROM
pg_index i
JOIN pg_class c ON i.indexrelid = c.oid
WHERE
-- New index built using REINDEX CONCURRENTLY
c.relname LIKE '%_ccnew'
-- In INVALID state
AND NOT indisvalid
LIMIT 10;
Once the rebuild process is no longer active, it should be safe to drop any remaining invalid indexes.
Activating B-Tree Index Deduplication
PostgreSQL 13 introduced a new efficient way of storing duplicate values in B-Tree indexes called “B-Tree Deduplication”.
For each indexed value, a B-Tree index will hold in its leaf both the value and a pointer to the row (TID). The larger the indexed values, the larger the index. Up until PostgreSQL 12, when the index contained many duplicate values, all of these duplicate values would be stored in the index leaves. This is not very efficient and can take up a lot of space.
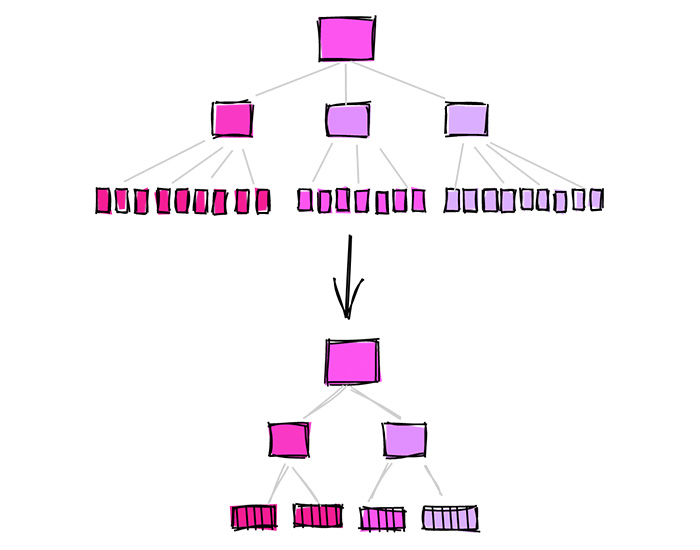 B-Tree Index Deduplication
B-Tree Index Deduplication
Starting at PostgreSQL 13, when B-Tree deduplication is activated, duplicate values are only stored once. This can make a huge impact on the size of indexes with many duplicate values.
In PostgreSQL 13 index deduplication in enabled by default, unless you deactivate it:
-- Activating de-deduplication for a B-Tree index, this is the default:
CREATE INDEX index_name ON table_name(column_name) WITH (deduplicate_items = ON)
If you are migrating from PostgreSQL versions prior to 13, you need to rebuild the indexes using the REINDEX command in order to get the full benefits of index de-deduplication.
To illustrate the effect of B-Tree deduplication on the size of the index, create a table with a unique column and a non unique column, and populate it with 1M rows. On each column create two B-Tree indexes, one with deduplication enabled and another with deduplication disabled:
db=# CREATE test_btree_dedup (n_unique serial, n_not_unique integer);
CREATE TABLE
db=# INSERT INTO test_btree_dedup (n_not_unique)
SELECT (random() * 100)::int FROM generate_series(1, 1000000);
INSERT 0 1000000
db=# CREATE INDEX ix1 ON test_btree_dedup (n_unique) WITH (deduplicate_items = OFF);
CREATE INDEX
db=# CREATE INDEX ix2 ON test_btree_dedup (n_unique) WITH (deduplicate_items = ON);
CREATE INDEX
db=# CREATE INDEX ix3 ON test_btree_dedup (n_not_unique) WITH (deduplicate_items = OFF);
CREATE INDEX
db=# CREATE INDEX ix4 ON test_btree_dedup (n_not_unique) WITH (deduplicate_items = ON);
CREATE INDEX
Next, compare the sizes of the four indexes:
| Column | Deduplication | Size |
|---|---|---|
| Not unique | Yes | 6840 kB |
| Not unique | No | 21 MB |
| Unique | Yes | 21 MB |
| Unique | No | 21 MB |
As expected, deduplication had no effect on the unique index, but it had a significant effect on the index that had many duplicate values.
Unfortunately for us, PostgreSQL 13 was still fresh at the time, and our cloud provider did not have support for it yet, so we were unable to use deduplication to clear space.
Clearing Bloat in Tables
Just like in indexes, tables can also contain dead tuples that cause bloat and fragmentation. However, unlike indexes that contain data from an associated table, a table can not just simply be re-created. To re-create a table you would have to create a new table, migrate the data over while keeping it synced with new data, create all the indexes, constraints and any referential constraints in other tables. Only after all of this is done, you can switch the old table with the new one.
 Clearing bloat in Tables
Clearing bloat in Tables
There are several ways to rebuild a table and reduce bloat:
-
Re-create the table: Using this method as described above often requires a lot of development, especially if the table is actively being used as it’s being rebuilt.
-
Vacuum the table: PostgreSQL provides a way to reclaim space occupied by bloat and dead tuples in a table using the VACUUM FULL command. Vacuum full requires a lock on the table, and is not an ideal solution for tables that need to be available while being vacuumed:
-- Will lock the table
VACUUM FULL table_name;
The two options above require either a significant effort, or some down time.
Using pg_repack
Both built-in options for rebuilding tables are not ideal unless you can afford downtime. One popular solution for rebuilding tables and indexes without downtime is the pg_repack extension.
Being a popular extension, pg_repack is likely available from your package manager or already installed by your cloud provider. To use pg_repack, you first need to create the extension:
CREATE EXTENSION pg_repack;
To “repack” a table along with its indexes, issue the following command from the console:
$ pg_repack -k --table table_name db_name
To rebuild a table with no downtime, the extension creates a new table, loads the data from the original table into it while keeping it up to date with new data, and then also rebuilds the indexes. When the process is finished, the two tables are switched and the original table is dropped. See here for full details.
pg_repack is a supported extensions for PostgreSQL on Amazon RDS. You can find more details on how to use pg_repack on AWS RDS.
There are two caveats to be aware of when using pg_repack to rebuild tables:
-
Requires amount of storage roughly the amount of the table to rebuild: the extension creates another table to copy the data to, so it requires additional storage roughly the size of the table and its indexes.
-
May require some manual cleanup: if the “repack” process failed or stopped manually, it may leave intermediate objects laying around, so you may need to do some manual cleanup.
Despite these caveats, pg_repack is a great option for rebuilding tables and indexes with no downtime. However, because it requires some additional storage to operate, it’s not a good option when you are already out of storage. It’s a good idea to monitor the free storage space and plan rebuilds in advance.
The “Find”
At this point we already used all the conventional techniques we could think of and cleared up a lot of space. We dropped unused indexes and cleared bloat from tables and indexes, but… there was still more space to shave off!
The “Aha Moment”
While we were looking at the sizes of the indexes after we finished rebuilding them, an interesting thing caught our eye.
One of our largest tables stores transaction data. In our system, after a payment is made, the user can choose to cancel and get a refund. This is not happening very often, and only a fraction of the transactions end up being cancelled.
In our transactions table, there are foreign keys to both the purchasing user and the cancelling user, and each field has a B-Tree index defined on it. The purchasing user has a NOT NULL constraint on it so all the rows hold a value. The cancelling user on the other hand, is nullable, and only a fraction of the rows hold any data. Most of the values in the cancelling user field are NULL.
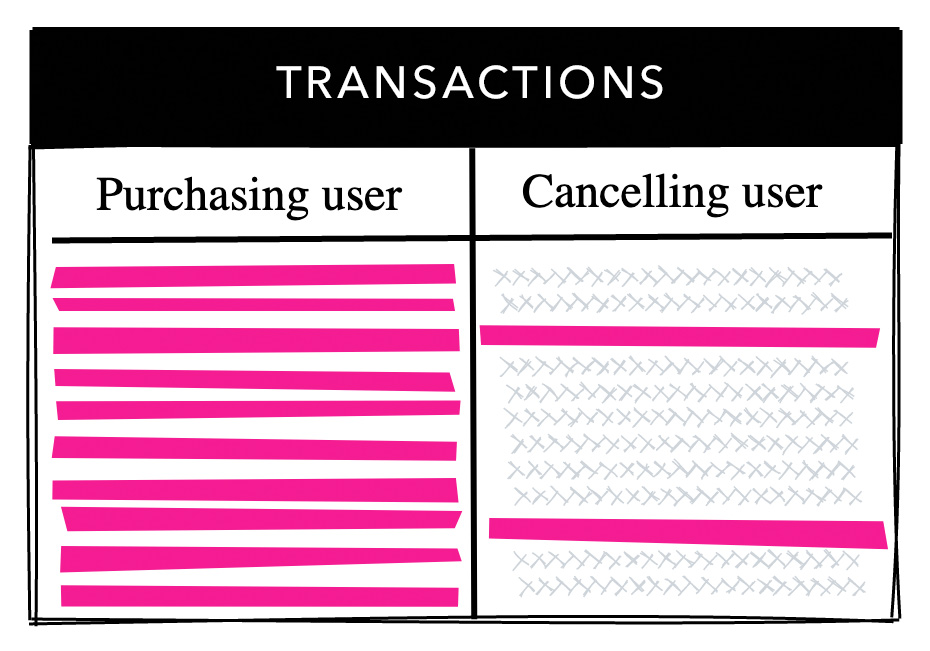 Transactions table with FK to purchasing and cancelling user
Transactions table with FK to purchasing and cancelling user
We expected the index on the cancelling user to be significantly smaller than the index on the purchasing user, but they were exactly the same. Coming from Oracle, I was always thought that NULLs are not indexed, but in PostgreSQL they are! This “Aha” moment led us to the realization that we were indexing a lot of unnecessary values for no reason.
This was the original index we had for the cancelling user:
CREATE INDEX transaction_cancelled_by_ix ON transactions(cancelled_by_user_id);
To check our thesis, we replaced the index with a partial index that excludes null values:
DROP INDEX transaction_cancelled_by_ix;
CREATE INDEX transaction_cancelled_by_part_ix ON transactions(cancelled_by_user_id)
WHERE cancelled_by_user_id IS NOT NULL;
The full index after we reindexed it was 769MB in size, with more than 99% null values. The partial index that excluded null values was less than 5MB. That’s more than 99% percent of dead weight shaved off the index!
| Index | Size |
|---|---|
| Full index | 769MB |
| Partial Index | 5MB |
| Difference | -99% |
To make sure those NULL values were indeed unnecessary, we reset the stats on the table and waited a while. Not long after, we observed that the index is being used just like the old one! We just shaved off more than 760MB of unused indexed tuples without compromising performance!
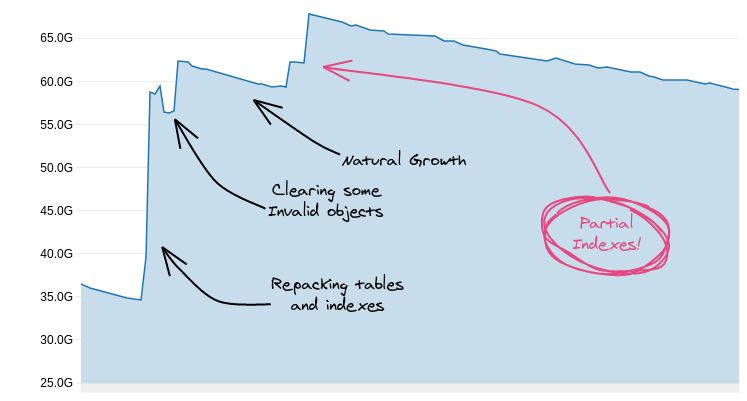 Clearing space, play by play
Clearing space, play by play
Utilizing Partial Indexes
Once we had a good experience with one partial index, we figured we might have more indexes like that. To find good candidates for partial index we wrote a query to search for indexes on fields with high null_frac, the percent of values of the column that PostgreSQL estimates are NULL:
-- Find indexed columns with high null_frac
SELECT
c.oid,
c.relname AS index,
pg_size_pretty(pg_relation_size(c.oid)) AS index_size,
i.indisunique AS unique,
a.attname AS indexed_column,
CASE s.null_frac
WHEN 0 THEN ''
ELSE to_char(s.null_frac * 100, '999.00%')
END AS null_frac,
pg_size_pretty((pg_relation_size(c.oid) * s.null_frac)::bigint) AS expected_saving
-- Uncomment to include the index definition
--, ixs.indexdef
FROM
pg_class c
JOIN pg_index i ON i.indexrelid = c.oid
JOIN pg_attribute a ON a.attrelid = c.oid
JOIN pg_class c_table ON c_table.oid = i.indrelid
JOIN pg_indexes ixs ON c.relname = ixs.indexname
LEFT JOIN pg_stats s ON s.tablename = c_table.relname AND a.attname = s.attname
WHERE
-- Primary key cannot be partial
NOT i.indisprimary
-- Exclude already partial indexes
AND i.indpred IS NULL
-- Exclude composite indexes
AND array_length(i.indkey, 1) = 1
-- Larger than 10MB
AND pg_relation_size(c.oid) > 10 * 1024 ^ 2
ORDER BY
pg_relation_size(c.oid) * s.null_frac DESC;
The results of this query can look like this:
oid | index | index_size | unique | indexed_column | null_frac | expected_saving
---------+--------------------+------------+--------+----------------+-----------+-----------------
138247 | tx_cancelled_by_ix | 1418 MB | f | cancelled_by | 96.15% | 1363 MB
16988 | tx_op1_ix | 1651 MB | t | op1 | 6.11% | 101 MB
1473377 | tx_token_ix | 22 MB | t | token | 11.21% | 2494 kB
138529 | tx_op_name_ix | 1160 MB | t | name | | 0 bytes
In the table above we can identify several types of results:
tx_cancelled_by_ixis a large index with many null values: great potential here!tx_op_1_ixis a large index with few null values: there’s not much potentialtx_token_ixis a small index with few null values: I wouldn’t bother with this indextx_op_name_ixis a large index with no null values: nothing to do here
The results show that by turning tx_cancelled_by_ix into a partial index that excludes null we can potentially save ~1.3GB.
Is it always beneficial to exclude nulls from indexes?
No. NULL is as meaningful as any other value. If your queries are searching for null values using IS NULL, these queries might benefit from an index on NULL.
So is this method beneficial only for null values?
Using partial indexes to exclude values that are not queried very often or not at all can be beneficial for any value, not just null values. NULL usually indicate a lack of value, and in our case not many queries were searching for null values, so it made sense to exclude them from the index.
So how did you end up clearing more than 20GB?
You may have noticed that the title mentions more than 20GB of free space but the charts only show half, well… indexes are also dropped from replications! When you release 10GB from your primary database, you also release roughly the same amount of storage from each replica.
Bonus: Migrating with Django ORM
This story is taken from a large application built with Django. To put the above techniques to practice with Django, there are several things to note.
Prevent Implicit Creation of Indexes on Foreign Keys
Unless you explicitly set db_index=False, Django will implicitly create a B-Tree index on a models.ForeignKey field. Consider the following example:
from django.db import models
from django.contrib.auth.models import User
class Transaction(models.Model):
# ...
cancelled_by_user = models.ForeignKey(
to=User,
null=True,
on_delete=models.CASCADE,
)
The model is used to keep track of transaction data. If a transaction is cancelled, we keep a reference to user that cancelled it. As previously described, most transactions don’t end up being cancelled, so we set null=True on the field.
In the ForeignKey definition above we did not explicitly set db_index, so Django will implicitly create a full index on the field. To create a partial index instead, make the following changes:
from django.db import models
from django.contrib.auth.models import User
class Transaction(models.Model):
# ...
cancelled_by_user = models.ForeignKey(
to=User,
null=True,
on_delete=models.CASCADE,
db_index=False,
)
class Meta:
indexes = (
models.Index(
fields=('cancelled_by_user_id', ),
name='%(class_name)s_cancelled_by_part_ix',
condition=Q(cancelled_by_user_id__isnull=False),
),
)
We first tell Django not to create the index on the FK field, and then add a partial index using models.Index.
Nullable foreign keys are good candidates for a partial index!
To prevent implicit features such as this one from sneaking indexes without us noticing, we create Django checks to force ourselves to always explicitly set db_index in foreign keys.
Migrate Exiting Full Indexes to Partial Indexes
One of the challenges we were facing during this migration is to replace the existing full indexes with partial indexes without causing downtime or degraded performance during the migration. After we identified the full indexes we want to replace, we took the following steps:
-
Replace full indexes with partial indexes: Adjust the relevant Django models and replace full indexes with partial indexes, as demonstrated above. The migration Django generates will first disable the FK constraint (if the field is a foreign key), drop the existing full index and create the new partial index. Executing this migration may cause both downtime and degraded performance, so we won’t actually run it.
-
Create the partial indexes manually: Use Django’s
./manage.py sqlmigrateutility to produce a script for the migration, extract only the CREATE INDEX statements and adjust them to create the indexes CONCURRENTLY. Then, create the indexes manually and concurrently in the database. Since the full indexes are not dropped yet, they can still be used by queries so performance should not be impacted in the process. It is possible to create indexes concurrently in Django migrations, but this time we decided it’s best to do it manually. -
Reset full index statistics counters: To make sure it’s safe to drop the full indexes, we wanted to first make sure the new partial indexes are being used. To keep track of their use we reset the counters for the full indexes using
pg_stat_reset_single_table_counters(<full index oid>). -
Monitor use of partial indexes: After reseting the stats we monitored both overall query performance and the partial index usage by observing the values of
idx_scan,idx_tup_readandidx_tup_fetchin thepg_stat_all_indexestables, for both the partial and the full indexes. -
Drop the full indexes: Once we were convinced the partial indexes are being used, we dropped the full indexes. This is a good point to check the sizes of both partial and full indexes to find out exactly how much storage you are about to free.
-
Fake the Django migration: Once the database state was effectively in-sync with the model state, we fake the migration using
./manage.py migrate --fake. When faking a migration, Django will register the migration as executed, but it won’t actually execute anything. This is useful for situations like this when you need better control over a migration process. Note that on other environments such as dev, QA or staging where there is not downtime considerations, the Django migrations will execute normally and the full indexes will be replaced with the partial ones. For more advanced Django migration operations such as “fake”, check out How to Move a Django Model to Another App.
Conclusion
Optimizing disks, storage parameters and configuration can only affect performance so much. At some point, to squeeze that final drop of performance you need to make changes to the underlying objects. In this case, it was the index definition.
To sum up the process we took to clear an much storage as we could:
- Remove unused indexes
- Repack tables and indexes (and activate B-Tree deduplication when possible)
- Utilize partial indexes to index only what’s necessary
Hopefully, after applying these techniques you can gain a few more days before you need to reach into your pocket and provision more storage.
Share this article: Click here to share this article on twitter.