


Postgres 16: Cumulative I/O statistics with pg_stat_io
 By Lukas Fittl
By Lukas FittlOne of the most common questions I get from people running Postgres databases at scale is:
How do I optimize the I/O operations of my database?
Historically, getting a complete picture of all the I/O produced by a Postgres server has been challenging. To start with, Postgres splits its I/O activity into writing the WAL stream, and reads/writes to the data directory. The real challenge is understanding second-order effects around writes: Typically the write to the data directory happens after the transaction commits, and understanding which process actually writes to the data directory (and when) is hard.
This whole situation has become an even bigger challenge in the cloud, when faced with provisioned IOPS, or worse, having to pay for individual I/Os like on Amazon Aurora. Often the solution has been to look at parts of the system that have instrumentation (such as individual queries), to get at least some sense for where the activity is happening.
Last weekend, a major improvement to the visibility into I/O activity was committed to the upcoming Postgres 16 by Andres Freund, and authored by Melanie Plageman, with documentation contributed by Samay Sharma. My colleague Maciek Sakrejda and I have reviewed this patch through its various iterations, and we’re very excited about what it brings to Postgres observability.
Welcome, pg_stat_io. Let’s take a look:
Querying system-wide I/O statistics in Postgres
Let’s start by using a local Postgres built fresh from the development branch. Note that Postgres 16 is still under heavy development, not even at beta stage, and should definitely not be used on production. For this I followed the new cheatsheet for using the Meson build system (also new in Postgres 16), which significantly speeds up the build and test process.
We can start by querying pg_stat_io to get a sense for which information is tracked, omitting rows that are empty:
SELECT * FROM pg_stat_io WHERE reads <> 0 OR writes <> 0 OR extends <> 0;
backend_type | io_object | io_context | reads | writes | extends | op_bytes | evictions | reuses | fsyncs | stats_reset
---------------------+-----------+------------+----------+---------+---------+----------+-----------+----------+--------+-------------------------------
autovacuum launcher | relation | normal | 19 | 5 | | 8192 | 13 | | 0 | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | normal | 15972 | 2494 | 2894 | 8192 | 17430 | | 0 | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | vacuum | 5754853 | 3006563 | 0 | 8192 | 2056 | 5752594 | | 2023-02-13 11:50:27.583875-08
client backend | relation | bulkread | 25832582 | 626900 | | 8192 | 753962 | 25074439 | | 2023-02-13 11:50:27.583875-08
client backend | relation | bulkwrite | 4654 | 2858085 | 3259572 | 8192 | 998220 | 2209070 | | 2023-02-13 11:50:27.583875-08
client backend | relation | normal | 960291 | 376524 | 159497 | 8192 | 1103707 | | 0 | 2023-02-13 11:50:27.583875-08
client backend | relation | vacuum | 128710 | 0 | 0 | 8192 | 1221 | 127489 | | 2023-02-13 11:50:27.583875-08
background worker | relation | bulkread | 39059938 | 590896 | | 8192 | 802939 | 38253662 | | 2023-02-13 11:50:27.583875-08
background worker | relation | normal | 257533 | 118972 | 0 | 8192 | 256437 | | 0 | 2023-02-13 11:50:27.583875-08
background writer | relation | normal | | 243142 | | 8192 | | | 0 | 2023-02-13 11:50:27.583875-08
checkpointer | relation | normal | | 390141 | | 8192 | | | 18812 | 2023-02-13 11:50:27.583875-08
standalone backend | relation | bulkwrite | 0 | 0 | 8 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
standalone backend | relation | normal | 689 | 983 | 470 | 8192 | 0 | | 0 | 2023-02-13 11:50:27.583875-08
standalone backend | relation | vacuum | 10 | 0 | 0 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
(14 rows)
At a high level, this information can be interpreted as:
- Statistics are tracked for a given backend type, I/O object type (i.e. whether it’s a temporary table), and I/O context (more on that later)
- The main statistics are counting I/O operations: reads, writes and extends (a special kind of write to resize data files)
- For each I/O operation the size in bytes is noted to help interpret the statistics (currently always block size, i.e., usually 8kB)
- Additionally, the number of shared buffer evictions, ring buffer re-uses and fsync calls are tracked
On Postgres 16, this system-wide information will always available. You can find the complete details of each field in the Postgres documentation.
Note that pg_stat_io shows logical I/O operations issued by Postgres. Whilst this often eventually maps to an actual I/O to a disk (especially in the case of writes), the operating system has its own caching and batching mechanism, and will for example often times split up an 8kB write to become two individual 4kB writes to the file system.
Generally we can assume that this captures all I/O issued by Postgres, except for:
- I/O for writing the Write-Ahead-Log (WAL)
- Special cases such as tables being moved between tablespaces
- Temporary files (such as used for sorts, or extensions like
pg_stat_statements)
Note that temporary relations are tracked (they are not the same as temporary files): In pg_stat_io these are marked as io_object = "temp relation" - you may otherwise be familiar with them being called “local buffers” in other statistics views.
With the basics in place, we can take a closer look at some use cases and learn why this matters.
Use cases for pg_stat_io
Tracking Write I/O activity in Postgres
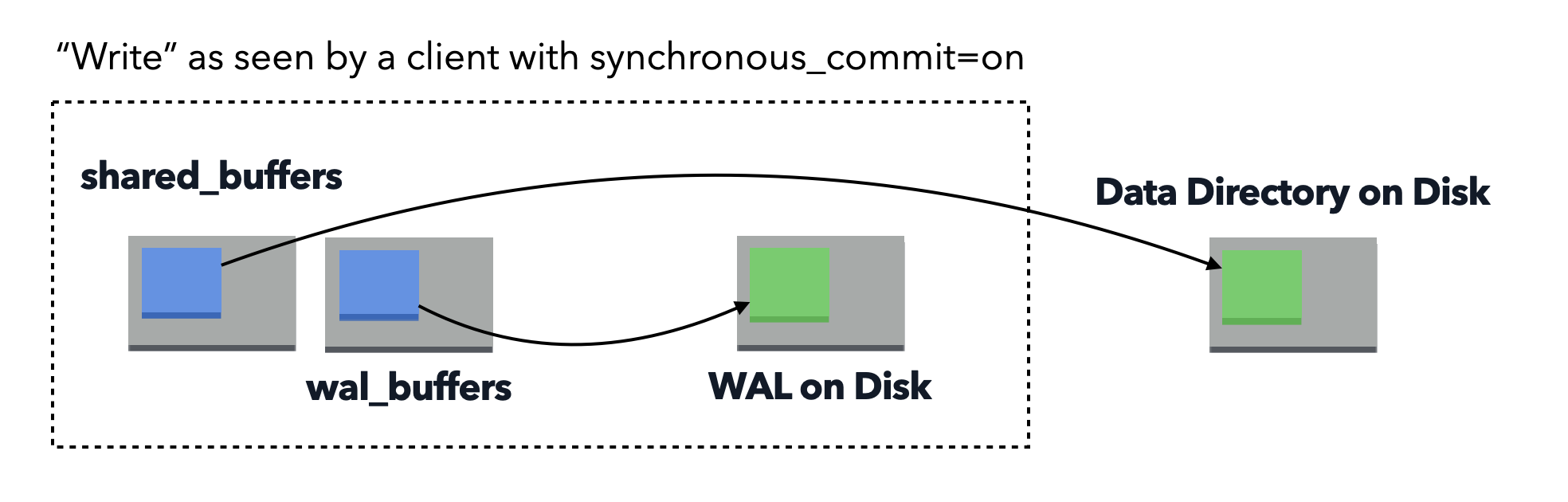
When looking at a write in Postgres, we need to look beyond what a client sees as the query runtime, or something like pg_stat_statements can track. Postgres has a complex set of mechanisms that guarantee durability of writes, whilst allowing clients to return quickly, trusting that the server has persisted the data in a crash safe manner.
The first thing that Postgres does to persist data, is to write it to the WAL log. Once this has succeeded, the client will receive confirmation that the write has been successful. But what happens afterwards is where the additional statistics tracking comes in handy.
For example, if you look at a given INSERT statement in pg_stat_statements, the shared_blks_written field is often going to tell you next to nothing, because the actual write to the data directory typically occurs at a later time, in order to batch writes for efficiency and to avoid I/O spikes.
In addition to writing the WAL, Postgres will also update the shared (or local) buffers for the write. Such an update will mark the buffer page in question as “dirty”.
Then, in most cases, another process is responsible for actually writing the dirty page to the data directory. There are three main process types to consider:
- The background writer: Runs continuously in the background to write out (some) dirty pages
- The checkpointer: Runs on a scheduled basis, or based on amount of WAL written, and writes out all dirty pages not yet written
- All other process types, including regular client backends: Write out dirty pages if they need to evict the buffer page in question
The main thing to understand is when the third case occurs - because it can drastically slow down queries. Even a simple “SELECT” might have to suddenly write to disk, before it has enough space in shared buffers to read in its data.
Historically you were already able to see some of this activity through the pg_stat_bgwriter view, specifically the fields named buffers_. However, this was incomplete, did not consider autovacuum activity explicitly, and did not let you understand the root cause of a write (e.g. a buffer eviction).
With pg_stat_io you can simply look at the writes field, and see both an accurate aggregate number, as well as exactly which process in Postgres actually ended up writing your data to disk.
Improve workload stability and sizing shared_buffers by monitoring shared buffer evictions
One of the most important metrics that pg_stat_io helps give clarity on, is the situation where a buffer page in shared buffers is evicted. Since shared buffers is a fixed size pool of pages (each 8kb in size, on most Postgres systems), what is cached inside it matters a great deal - especially when your working set exceeds shared buffers.
By default, if you’re on a self-managed Postgres, the shared_buffers setting is set to 128MB - or about 16,000 pages. Let’s imagine you end up having loaded something through a very inefficient index scan, that ended up consuming all 128MB.
What happens when you suddenly read something completely different? Postgres has to go and remove some of the old data from cache - also known as evicting a buffer page.
This eviction has two main effects:
- Data that was in Postgres buffer cache before, is no longer in the cache (note it may still be in the OS page cache)
- If the page that was evicted was marked as “dirty”, the process evicting it also has to write the old page to disk
Both of these aspects matter for sizing shared buffers, and pg_stat_io can clearly show this by tracking evictions for each backend type across the system. Further, if you see a sudden spike in evictions, and then suddenly a lot of reads, it can help you infer that the cached data that was evicted, was actually needed again shortly afterwards. If in doubt, you can use the pg_buffercache extension to look at the current shared buffers contents in detail.

Tracking cumulative I/O activity by autovacuum and manual VACUUMs
It’s a fact that every Postgres server needs the occasional VACUUM - whether you schedule it manually, or have autovacuum take care of it for you. It helps clean up dead rows and makes space re-usable, and it freezes pages to prevent transaction ID wraparound.
But there is such a thing as VACUUMing too often. If not tuned correctly, VACUUM and autovacuum can have a dramatic effect on I/O activity. Historically the best bet was to look at the output of log_autovacuum_min_duration, which will give you information like this:
LOG: automatic vacuum of table "mydb.pg_toast.pg_toast_42593": index scans: 0
pages: 0 removed, 13594 remain, 13594 scanned (100.00% of total)
tuples: 0 removed, 54515 remain, 0 are dead but not yet removable
removable cutoff: 11915, which was 6 XIDs old when operation ended
new relfrozenxid: 11915, which is 4139 XIDs ahead of previous value
frozen: 13594 pages from table (100.00% of total) had 54515 tuples frozen
index scan not needed: 0 pages from table (0.00% of total) had 0 dead item identifiers removed
avg read rate: 0.113 MB/s, avg write rate: 0.113 MB/s
buffer usage: 13614 hits, 13602 misses, 13600 dirtied
WAL usage: 40786 records, 13600 full page images, 113072608 bytes
system usage: CPU: user: 0.26 s, system: 0.52 s, elapsed: 939.84 s
From the buffer usage you can determine that this single VACUUM had to read 13602 pages, and marked 13600 pages as dirty. But what if we want to get a more complete picture, and across all our VACUUMs?
With pg_stat_io, you can now see a system-wide measurement of the impact of VACUUM, by looking at everything marked as io_context = 'vacuum', or associated to the autovacuum worker backend type:
SELECT * FROM pg_stat_io WHERE backend_type = 'autovacuum worker' OR (io_context = 'vacuum' AND (reads <> 0 OR writes <> 0 OR extends <> 0));
backend_type | io_object | io_context | reads | writes | extends | op_bytes | evictions | reuses | fsyncs | stats_reset
--------------------+-----------+------------+---------+---------+---------+----------+-----------+---------+--------+-------------------------------
autovacuum worker | relation | bulkread | 0 | 0 | | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | normal | 16306 | 2494 | 2915 | 8192 | 17785 | | 0 | 2023-02-13 11:50:27.583875-08
autovacuum worker | relation | vacuum | 5824251 | 3028684 | 0 | 8192 | 2588 | 5821460 | | 2023-02-13 11:50:27.583875-08
client backend | relation | vacuum | 128710 | 0 | 0 | 8192 | 1221 | 127489 | | 2023-02-13 11:50:27.583875-08
standalone backend | relation | vacuum | 10 | 0 | 0 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
(5 rows)
In this particular example, in sum, the autovacuum worker has read 44.4 GB of data (5,824,251 buffer pages), and written 23.1GB (3,028,684 buffer pages).
If you track these statistics over time, it will help you have a crystal-clear picture of whether autovacuum is to blame for an I/O spike during business hours. It will also help you make changes to tune autovacuum with more confidence, e.g. making autovacuum more aggressive to prevent bloat.
Visibility into bulk read/write strategies (sequential scans and COPY)
Have you ever used COPY in Postgres to load data? Or read data from a table using a sequential scan? You may not know that in most cases, this data does not pass through shared buffers in the regular way. Instead, Postgres uses a special dedicated ring buffer that ensures that most of shared buffers is undisturbed by such large activities.
Before pg_stat_io, it was near impossible to understand this activity in Postgres, as there was simply no tracking for it. Now, we can finally see both bulk reads (typically large sequential scans) and bulk writes (typically COPY in), and the I/O activity they cause.
You can simply filter for the new bulkwrite and bulkread values in io_context, and have visibility into this activity:
SELECT * FROM pg_stat_io WHERE io_context IN ('bulkread', 'bulkwrite') AND (reads <> 0 OR writes <> 0 OR extends <> 0);
backend_type | io_object | io_context | reads | writes | extends | op_bytes | evictions | reuses | fsyncs | stats_reset
--------------------+-----------+------------+----------+---------+---------+----------+-----------+----------+--------+-------------------------------
client backend | relation | bulkread | 25900458 | 627059 | | 8192 | 754610 | 25141667 | | 2023-02-13 11:50:27.583875-08
client backend | relation | bulkwrite | 4654 | 2858085 | 3259572 | 8192 | 998220 | 2209070 | | 2023-02-13 11:50:27.583875-08
background worker | relation | bulkread | 39059938 | 590896 | | 8192 | 802939 | 38253662 | | 2023-02-13 11:50:27.583875-08
standalone backend | relation | bulkwrite | 0 | 0 | 8 | 8192 | 0 | 0 | | 2023-02-13 11:50:27.583875-08
(4 rows)
In this example, there is 495 GB of bulk read activity, and 21 GB of bulk write activity we had no good way of identifying before. However, and most importantly, we don’t have to worry about the evictions count here - these are all evictions from the special bulk read / bulk write ring buffer, not from regular shared buffers.
Sneak peek: Visualizing pg_stat_io in pganalyze
It’s still a while until Postgres 16 will be released (usually September or October each year), but to help test things (and because it’s exciting!) I took a quick stab at updating pganalyze in an experimental branch to collect pg_stat_io metrics and visualize them over time.
Here is a very early look at how this may look like in the future:
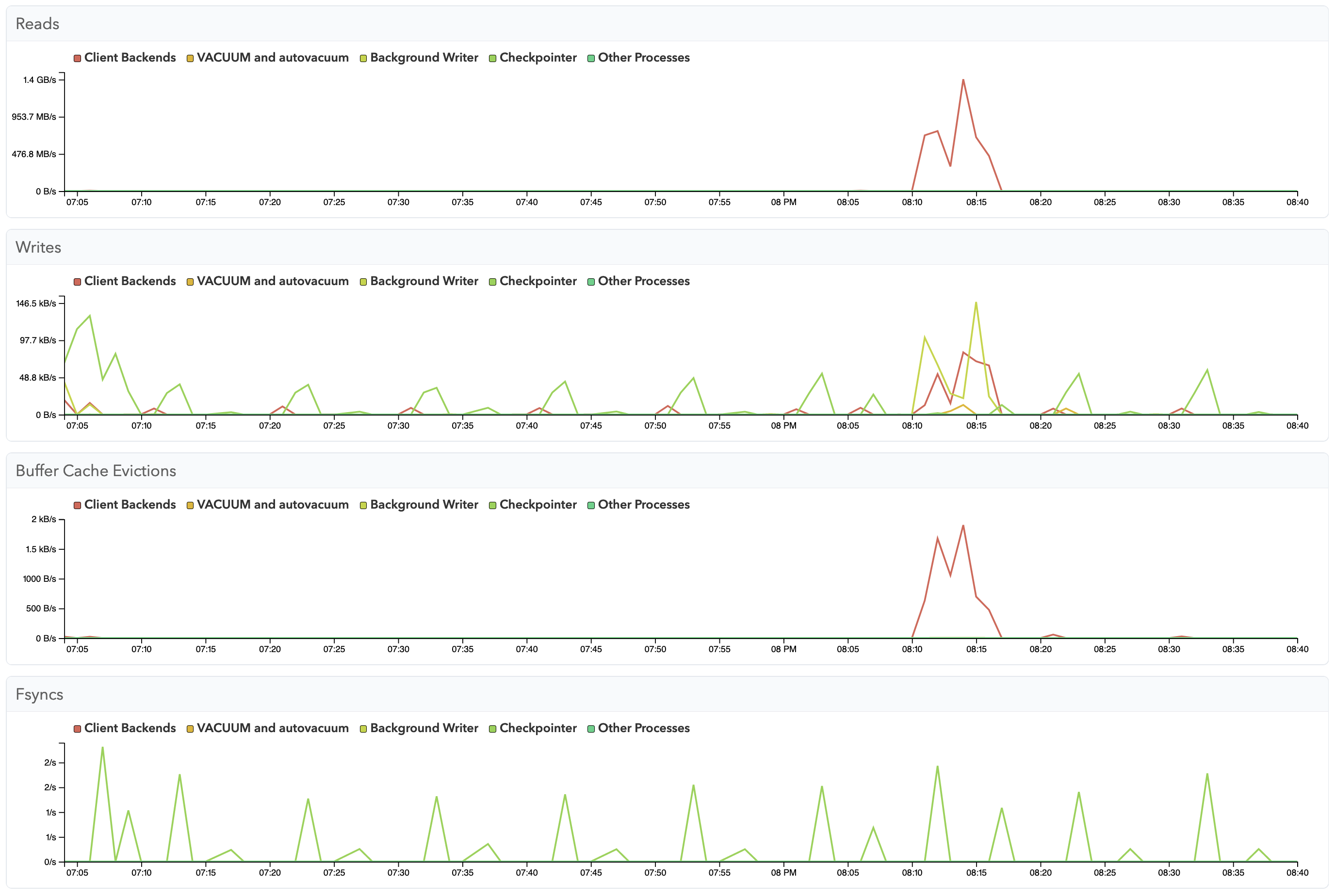
Even though this is just running locally on my laptop, already we can see a clear pattern where writes are done by the checkpointer and background writer processes, most of the time. We can also see my checkpoint_timeout being set to 5min (the default), with both writes and fsyncs happening like clockwork - note the workload is periodic every 10 minutes, so every second checkpoint has less work to do.
However, we can also clearly see a spike in activity - and that spike can be easily explained: To generate more database activity, I triggered a big daily background process around 8:10pm UTC. The high amount of data read caused the working set to momentarily exceed shared buffers, and caused a large amount of buffer evictions, which then caused the client backend having to write out buffer pages unexpectedly.
On this system I have a very small shared_buffers setting (the default, 128 MB). I should probably increase shared_buffers…
The future of I/O observability in Postgres
A lot of the ground work for pg_stat_io actually happened previously in Postgres 15, through the new cumulative statistics system using shared memory.
Before Postgres 15, statistics tracking had to go through the statistics collector (an obscure process that received UDP packets from individual processes part of Postgres), which was slow and error prone. This historically limited the ability to collect more advanced statistics easily. As the addition of pg_stat_io shows, it is now much easier to track additional information about how Postgres operates.
Amongst the immediate improvements that are already being discussed are:
- Tracking of system-wide buffer cache hits (to allow calculating an accurate buffer cache hit ratio)
- Cumulative system-wide I/O times (not just I/O counts as currently present in
pg_stat_io) - Better cumulative WAL statistics (i.e. going beyond what pg_stat_wal offers)
- Additional I/O tracking for tables and indexes
Our team at pganalyze is excited to have helped shape the new pg_stat_io view, and we look forward to continue working with the community on making Postgres better.
Share this article: If you’d like to share this article with your peers, you can tweet about it here.
PS: If you’re interested in learning more about optimizing Postgres I/O performance and costs you can check out our webinar recording.