
Waiting for Postgres 17: Faster VACUUM with Adaptive Radix Trees
 By Lukas Fittl
By Lukas FittlIn today’s E109 of “5mins of Postgres” we discuss a recently committed change to the Postgres 17 development branch that introduces an improved dead tuple storage for autovacuum based on adaptive radix trees. This significantly reduces autovacuum memory consumption and avoids the need for multiple index vacuum phases.
Share this episode: Click here to share this episode on LinkedIn or on X/Twitter. Feel free to sign up for our newsletter and subscribe to our YouTube channel.
Transcript
As always, when we talk about Postgres 17, it’s important to call out that these things might still change. Postgres 17 is expected to come out in September or October and a lot of testing will happen between now and then. We’re also about to be at feature freeze, so that means we’re getting close to getting the final set of features in Postgres 17 that will likely be in there.
Today, I want to talk about this commit by Masahiko Sawada from earlier this week, that improves how VACUUM stores dead tuples.
The building blocks: Adaptive Radix Trees and TIDStore
But let’s go back a little bit on the background of this commit first. So this starts earlier here, with the addition of an adaptive radix tree implementation to Postgres. This is a commit by John Naylor earlier in March. Ultimately the benefit of a radix tree is that it’s more memory efficient, and it’s able to handle sorted keys more efficiently.
As noted in that commit, the initial proof of concept here was built by Andres Freund, and then after subsequent discussions, Masahiko Sawada and John Naylor took this proof of concept and productionized it. So now in Postgres, we have this general purpose radix tree mechanism.
And this is based on a paper, The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases by a couple of researchers in Germany from 2013. Now, if you are interested in all the details of that paper, feel free to take a look. But for today, we’re going to focus on the Postgres benefits here. So in this commit Masahiko added the “TIDStore” based on this radix tree implementation. And if you’re not familiar, TIDs or tuple identifiers are essentially how Postgres is able to say, where is a particular row version or “tuple” located.
Why does this matter?
Dead Tuple Storage in Autovacuum
Now, of course, what’s a common place where you need this, is an autovacuum. When autovacuum or VACUUM processes dead tuples that were caused by an UPDATE or DELETE in your table, autovacuum needs to remember where those tuples were in the table whilst it’s vacuuming the indexes. The way this works is that the main table has a dead tuple, a dead row version, and then the index still points to that dead row. And so we need to go to the index, remove the stale index entries to then be able to actually fully remove the dead tuple on the main table.
And so this is one of the fundamental limits in autovacuum today on older Postgres versions is that you actually have a 1GB limit here in terms of how autovacuum keeps track of this. Which is essentially based on the fact that Postgres used to use, up until this commit, a simple array that stored these IDs. But now thanks to the adaptive radix tree implementation, this is much more memory efficient. The idea here is that autovacuum_work_mem still controls the size of the radix tree, but the benefit being that the radix tree is much more memory efficient, and so we will be able to keep many more dead tuple identifiers within the vacuum process, so we don’t have to do multiple index phases.
The Overhead of Multiple Index Phases
Multiple index phases, for context, that happens when autovacuum essentially runs out of working memory, and so it can’t remember enough dead tuple information and so it has to first go over all the indexes and then after it’s done, it needs to continue scanning the table. And so of course this means that we essentially have a lot of overhead for each of the indexes on our table because we have to vacuum it multiple times.
Benchmarking Postgres 16 vs 17
Now, let’s take a look at a practical example where this benefit can be seen. So locally, I have both Postgres 16, as well as Postgres 17 development branch as of earlier today, running, and so we’re going to compare this behavior of autovacuum between the two versions.
Test setup
I can also show you here that the autovacuum_work_mem is set to the default, which is “-1”, which means it takes the value from maintenance_work_mem. maintenance_work_mem is set to 64 megabytes on both of these. That means this is the maximum amount of memory that autovacuum can use. I could raise this 1 GB, but it’s actually more helpful to illustrate, so we will keep it low here.
I’m going to create a table on both 16 and 17. This table has a hundred million records:
CREATE TABLE test AS SELECT * FROM generate_series(1, 100000000) x(id);
And now we’re going to create an index:
CREATE INDEX ON test(id);
This is an important step because the improvement here only matters on tables with indexes, which in production most of the time, that’s the case.
Now let’s first take a look at the size of this table. This is a 3.4 GB table that we’re working with here.
And what I’m going to do is I’m going to update the whole table. And I’m essentially just going to reassign the IDs to be 1 less than they were before:
UPDATE test SET id = id - 1;
And of course, this is a pretty significant change here, right, we’re rewriting a hundred million rows, and I’m going to use my time travel machine to accelerate this little bit. Alright, wonderful. Now, that the UPDATE has finished, Postgres will automatically kick off an autovacuum for us. And so if we check the “pg_stat_progress_vacuum” view, we’ll see here that vacuum is running right now and as it’s running, it now has to scan over the table.
Postgres 16: A total of 9 Index VACUUM Phases!
And you can already see that we just had our first index vacuum phase. So autovacuum already, after what probably was less than 1 minute, already ran into the “autovacuum_work_mem” limit here. So 64 MB worth of dead tuples caused it to trigger an index vacuum phase. Now, after this index vacuum phase is done, we’ll see that the “index_vacuum_count” went up by one. We also see that now Postgres is vacuuming the rows that are marked as dead, and now it’s scanning the heap again so that it can find more dead row versions. It does this again up to that 64 MB limit it can remember, and now we’re vacuuming indexes this again. Now we’ll skip ahead a little bit again, until this is completed. It was a total of 9 index vacuum phases:
-[ RECORD 1 ]------+---------------
pid | 559
datid | 5
datname | postgres
relid | 16422
phase | vacuuming heap
heap_blks_total | 884956
heap_blks_scanned | 884956
heap_blks_vacuumed | 441819
index_vacuum_count | 9
max_dead_tuples | 11184809
num_dead_tuples | 10522080
And now we’re just vacuuming the heap, one last time. This is actually removing the dead rows. And there we go. Alright, this took quite a long time. So let’s take a look at the logs.
So Postgres autovacuum will produce a log output when you have it enabled:
2024-04-06 20:07:39.296 UTC [559] LOG: automatic vacuum of table "postgres.public.test": index scans: 9
pages: 0 removed, 884956 remain, 884956 scanned (100.00% of total)
tuples: 100000000 removed, 100000000 remain, 0 are dead but not yet removable
removable cutoff: 751, which was 1 XIDs old when operation ended
new relfrozenxid: 750, which is 4 XIDs ahead of previous value
frozen: 1 pages from table (0.00% of total) had 28 tuples frozen
index scan needed: 442478 pages from table (50.00% of total) had 100000000 dead item identifiers removed
index "test_id_idx": pages: 548383 in total, 0 newly deleted, 0 currently deleted, 0 reusable
avg read rate: 62.474 MB/s, avg write rate: 18.935 MB/s
buffer usage: 964903 hits, 6183317 misses, 1874043 dirtied
WAL usage: 2316372 records, 1189127 full page images, 2689898432 bytes
system usage: CPU: user: 78.21 s, system: 30.06 s, elapsed: 773.23 s
And this is quite dense and information rich, I would say, but the thing for now that we care about is that we ran for a total of 770 seconds to vacuum this table.
Postgres 17: Half the memory use, 1 index VACUUM phase
Let’s go to Postgres 17 and repeat the same exercise.
So we’re going to also execute our UPDATE statement. And now that the update has finished. We can once again watch the VACUUM that’s running. You can see here one of the differences between 16 and 17, is that in 17 we’re counting up dead tuple bytes, which is essentially how big that radix tree is, that is keeping dead tuple information.
And now as we scan more heap blocks, one thing that jumps out to me at least immediately is that we’ve already passed the number of blocks we scanned, compared to what we did on Postgres 16 and we didn’t kick off an index vacuum phase. That’s really the big benefit we can see here already is, we’re right now using about 13 MB of memory to remember a lot more dead tuples than we were able to remember on 16 in 64 megabytes. And so really this is the benefit is that we can now keep this metadata, we can keep scanning the heap, and then after it’s scanned, we’ll be able to do a vacuum index phase.
Let’s skip ahead to that. With only 37 megabytes of memory in use, we switched to the vacuuming indexes phase:
-[ RECORD 1 ]--------+------------------
pid | 56915
datid | 5
datname | postgres
relid | 16439
phase | vacuuming indexes
heap_blks_total | 884956
heap_blks_scanned | 884956
heap_blks_vacuumed | 0
index_vacuum_count | 0
max_dead_tuple_bytes | 67108864
dead_tuple_bytes | 37289984
indexes_total | 1
indexes_processed | 0
And so that means we only need a single index vacuum phase here now, which is a tremendous performance improvement. If you had multiple indexes to be scanned that are very large this could take substantial amounts of time, and we now have a single index vacuum phase, thanks to the adaptive radix tree.
-[ RECORD 1 ]--------+---------------
pid | 56915
datid | 5
datname | postgres
relid | 16439
phase | vacuuming heap
heap_blks_total | 884956
heap_blks_scanned | 884956
heap_blks_vacuumed | 439755
index_vacuum_count | 1
max_dead_tuple_bytes | 67108864
dead_tuple_bytes | 37289984
indexes_total | 0
indexes_processed | 0
Now with the vacuum finished, let’s look at our Postgres log output:
2024-04-06 13:26:37.571 PDT [56915] LOG: automatic vacuum of table "postgres.public.test": index scans: 1
pages: 0 removed, 884956 remain, 884956 scanned (100.00% of total)
tuples: 100000000 removed, 100000000 remain, 0 are dead but not yet removable
removable cutoff: 793, which was 1 XIDs old when operation ended
new relfrozenxid: 791, which is 5 XIDs ahead of previous value
frozen: 1 pages from table (0.00% of total) had 28 tuples frozen
index scan needed: 442478 pages from table (50.00% of total) had 100000000 dead item identifiers removed
index "test_id_idx": pages: 548383 in total, 0 newly deleted, 0 currently deleted, 0 reusable
avg read rate: 23.458 MB/s, avg write rate: 23.651 MB/s
buffer usage: 902391 hits, 1858721 misses, 1874025 dirtied
WAL usage: 2316363 records, 1431435 full page images, 2586981769 bytes
system usage: CPU: user: 78.84 s, system: 47.42 s, elapsed: 619.04 s
We can see that here, the total vacuum runtime was 619 seconds, compared to the 773 seconds on Postgres 16.
There’s one last thing I want to show you, which is a visual comparison of how this behavior differs.
Visualizing the difference in VACUUM phases
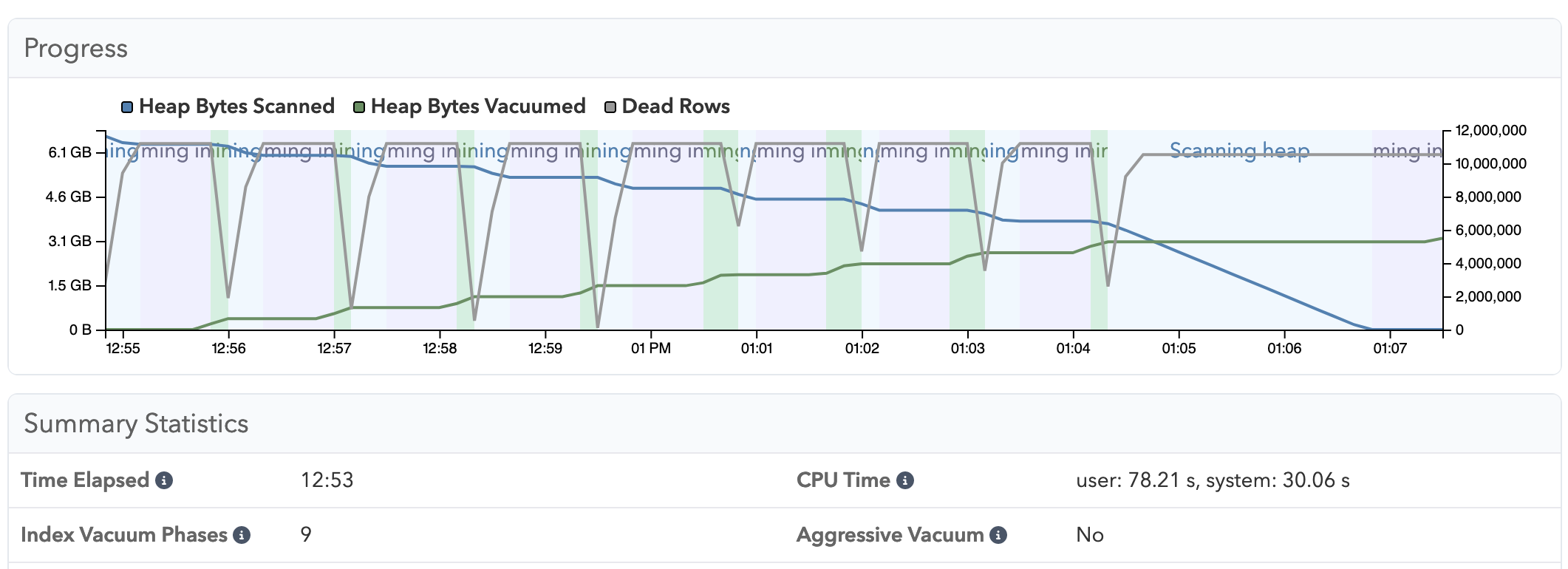
So here, this is pganalyze showing VACUUM statistics in Postgres 16. I’ll pull up the test run that finished there. You can see this staccato like behavior where Postgres keeps switching into the index vacuum phase and then switches back to vacuuming the heap:
Versus on 17, what we can see is the test run that just finished, has a single vacuuming index phase:
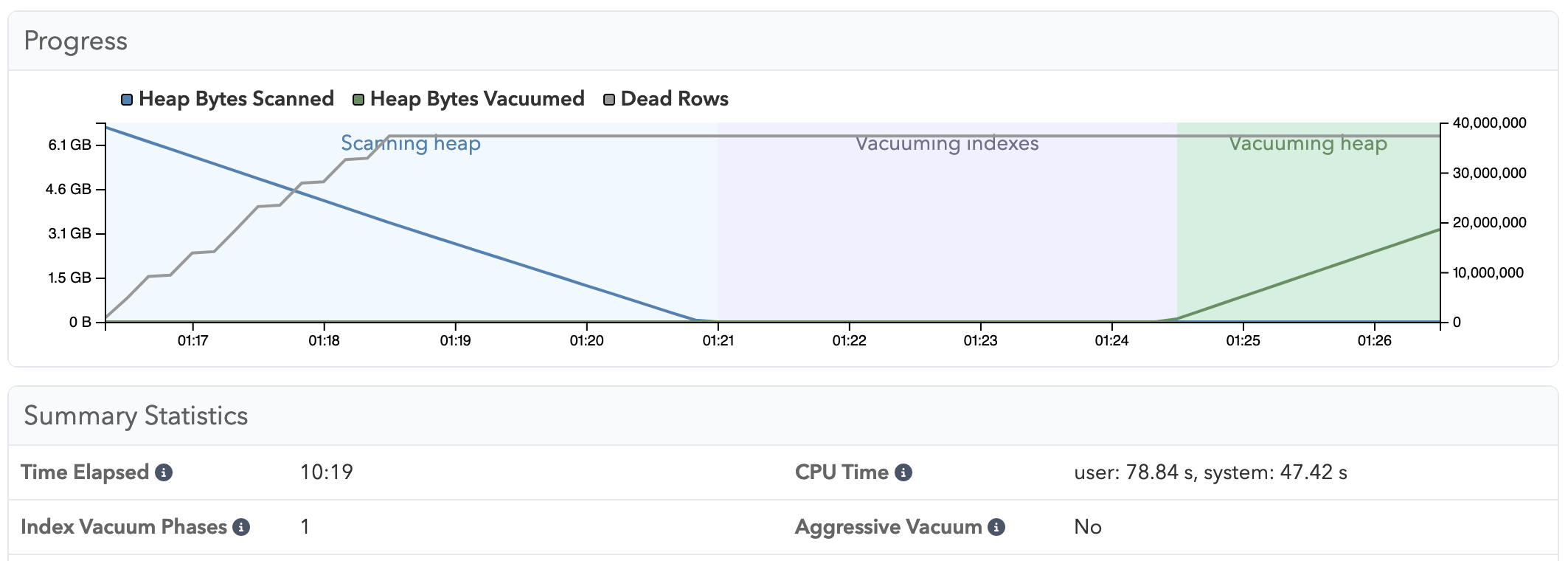
Just visually, if you compare those two graphs, I think it shows very clearly that 17 is significantly better, it will also have less churning in shared buffers, I’m really excited about this improvement in Postgres 17.
In conclusion
A big, thanks to Masahiko Sawada and John Naylor to get the adaptive radix tree implementation, as well as the TIDStore committed to Postgres. I think this autovacuum performance improvement is an excellent change, and I look forward to future use cases for radix trees inside Postgres.
I hope you learned something new from E109 of 5mins of Postgres. Feel free to subscribe to our YouTube channel, sign up for our newsletter or follow us on LinkedIn and X/Twitter to get updates about new episodes!