


Zero downtime Postgres upgrades and how to logically replicate very large tables
 By Lukas Fittl
By Lukas FittlIn E95 of “5mins of Postgres”, we talk about zero downtime Postgres upgrades and how to logically replicate very large tables. It’s an exciting episode packed with lots of real world experiences and examples from GitLab and Instacart!
Share this episode: Click here to share this episode on LinkedIn or on twitter. Feel free to sign up for our newsletter and subscribe to our YouTube channel.
- Using logical replication to update Postgres with zero downtime
- Upgrading Postgres with pg_upgrade
- Logical replication across different database versions
- Zero Downtime Postgres Cutovers
- Upgrading Postgres with logical replication and recovery_target_lsn
- Better understanding these approaches
- Blue green deployments on AWS RDS
- What we have discussed in this episode of 5mins of Postgres
Transcript
Using logical replication to update Postgres with zero downtime
First of all, we’ll start with this blog post by Brent Anderson on the Knock blog. Knock provides a product where they want to make sure that they have as little downtime as possible. They saw themselves face a Postgres major version upgrade from Postgres 11, which is now end of life, to Postgres 15, which is the second most recent Postgres release.
Now they wanted to have zero downtime and they used logical replication to achieve this. For additional context, they’re using a managed service provider, AWS Aurora. But until recently, Aurora did not have any mechanism to support what they now call blue green upgrades, which is a way to use logical replication for upgrades. So you essentially had to do it manually.
Upgrading Postgres with pg_upgrade
Now, first of all, there is a way to do upgrades without using logical replication, which is to just do what’s called in-place upgrade. So this is running the pg_upgrade command, which either your provider runs for you when you modify the Postgres version or if you’re on a self managed system, you can just run pg_upgrade.
“pg_upgrade” is usually very fast. It usually just takes a few minutes. There are sometimes edge cases, but generally speaking, “pg_upgrade” is the easiest way to do major version upgrades. But if you’re trying to keep downtime to minimum, because you absolutely cannot afford even a minute of downtime, then you need to be creative and find other solutions.
Logical replication across different database versions
You can have logical replication across different database versions. And so the general idea here is:
- We bring up a new database on a new Postgres version,
- We copy over all the tables,
- Then we set up a publication on the old database,
- We set up a logical replication subscription on the new database,
- and then we’re logically replicating tables to that new database.
Then, when you’re confident that everything looks good and you’re following that old database, you can point your application to the new database.
So really what logical replication allows us to do is have these two different versions running side by side.
Caveats of this approach
This is the approach that the team at Knock have use,, but there were a couple of caveats that they ran into. I would say the most important thing that they did is that they essentially went table by table, because the problem that they saw was that if they were to replicate too many tables at once, the initial synchronization of the table data would take too long. The copy that logical replication does by default takes too long. Then they saw issues like transaction wraparound on the old primary, because it had to retain all that transaction information whilst the initial data copy was happening. That’s the fundamental way of how logical replication works, by the way. You have to have that data copied whilst keeping open the replication slot! What they ended up doing is essentially copying these tables table by table and being a bit creative how to achieve it. Then ultimately, after a couple of checks, they cut over to the new database.
Interesting to mention, on Hacker News, there were quite a few comments on this approach. They were mainly revolving around: “this is very I/O heavy if you’re copying the tables like they’re doing, and that doesn’t really work if you have very large tables.” There are alternate approaches specifically for very large tables and there are two I want to talk about specifically.

Zero Downtime Postgres Cutovers
First of all, in the context of RDS, there is an approach that Instacart has developed. Earlier this year, they talked about zero downtime postgres cutovers.
Unfortunately, the tooling that they referenced here does not seem to be publicly available yet, so a better reference is actually their older blog post where they talk a little bit more about what they’re doing underneath the hood. Ultimately, what they described in that blog post is that they’re creating a replication slot on the primary, then they’re snapshotting the old primary, and then they’re restoring the snapshot and finally are advancing the replication slot. We’ll take another look at that in a moment.
It’s important to mention that there are some concerns that people have had over the years that there are certain edge cases specifically around transactions that are in flight when you’re doing that disk snapshot that may cause issues.
Upgrading Postgres with logical replication and recovery_target_lsn
In the above mentioned Hacker News thread, Nikolay from Postgres.ai also commented, and he described his work with the GitLab team on doing their upgrades on their self managed servers. This approach is a bit different. What Nikolay describes is an approach that you could, for example, run when you’re running on Patroni.
The idea is the following:
- You make a copy of your existing cluster
- You have that follow the old cluster using physical replication.
- You’re then stopping the new cluster.
- You’re creating a logical replication slot on the current primary.
- Then you’re using
recovery_target_lsnto catch up your physical replica to the specific LSN of the logical slot. - Then you start logically replicating.
recovery_target_lsn, just for context, is essentially a way for a stopped replica to be configured so that it will keep replaying until a particular logical sequence number, a particular position in the Postgres WAL stream, and then it will stop and essentially shut down again. You can use that, for example, in point-in-time recovery if you want to get to a very specific point.
This is great, as it’s much more precise than the approach that Instacart is describing, but you could only use that on your own server.
Better understanding these approaches
I wanted to quickly illustrate this for you, because I can imagine it is a bit hard to follow. On managed service providers, usually you don’t have control over primitives, such as recovery_target_lsn.
The approach that Instacart is describing is that you’re creating that logical replication slot first, you then make a disk snapshot, then you look at which LSN did that disk snapshot, take the snapshot off, and then you advancing your logical replication slot to that point, then you can do your upgrade and then you’re logically replicating based on that disk snapshot.
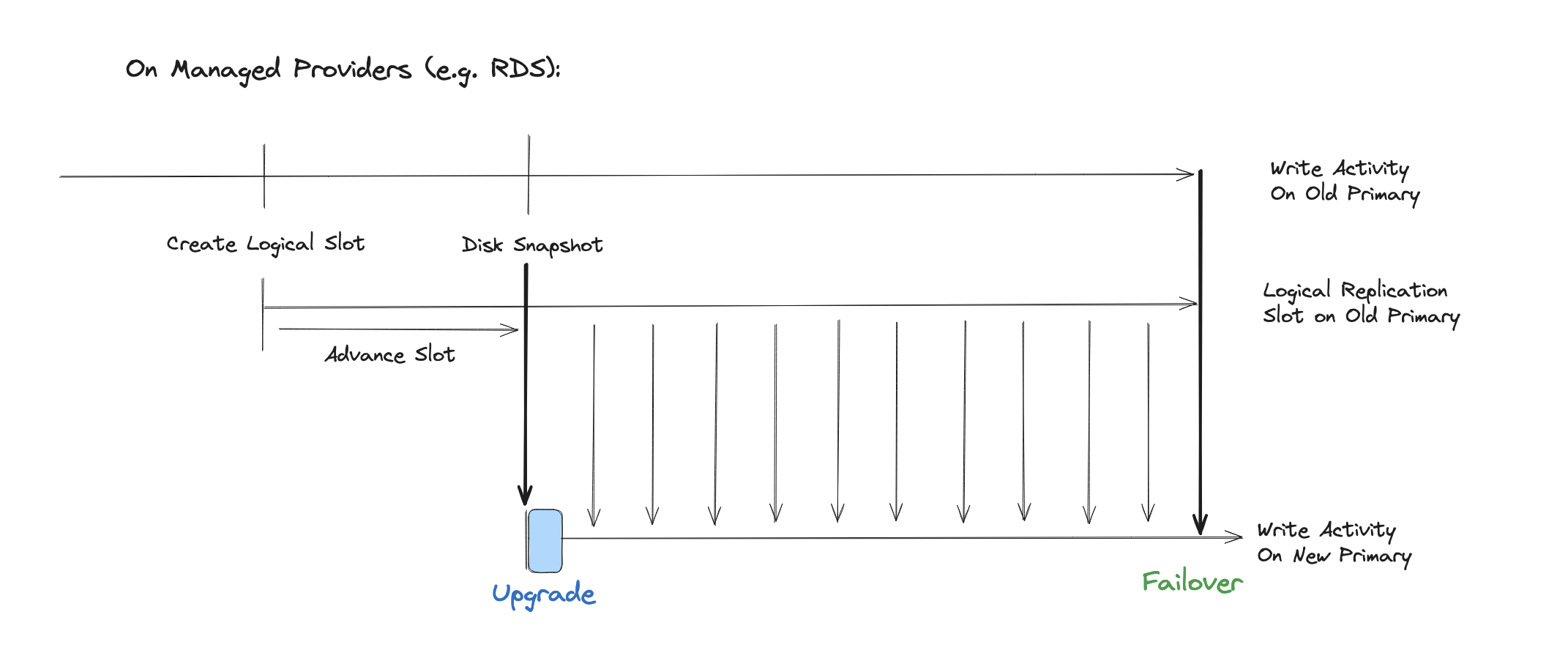
That lets you avoid all the table copy, it has the benefit of supporting very large tables easily, but there’s a bit of a risk here of relying on the exact semantics of a disk snapshot.
The self-managed approach that Nikolay is describing is much safer, I would argue, but you can, of course, only run this if you’re running Postgres yourself, which is to create a physical replica, for example, with pg_basebackup, then you’re physically replicating – just regular WAL replication.
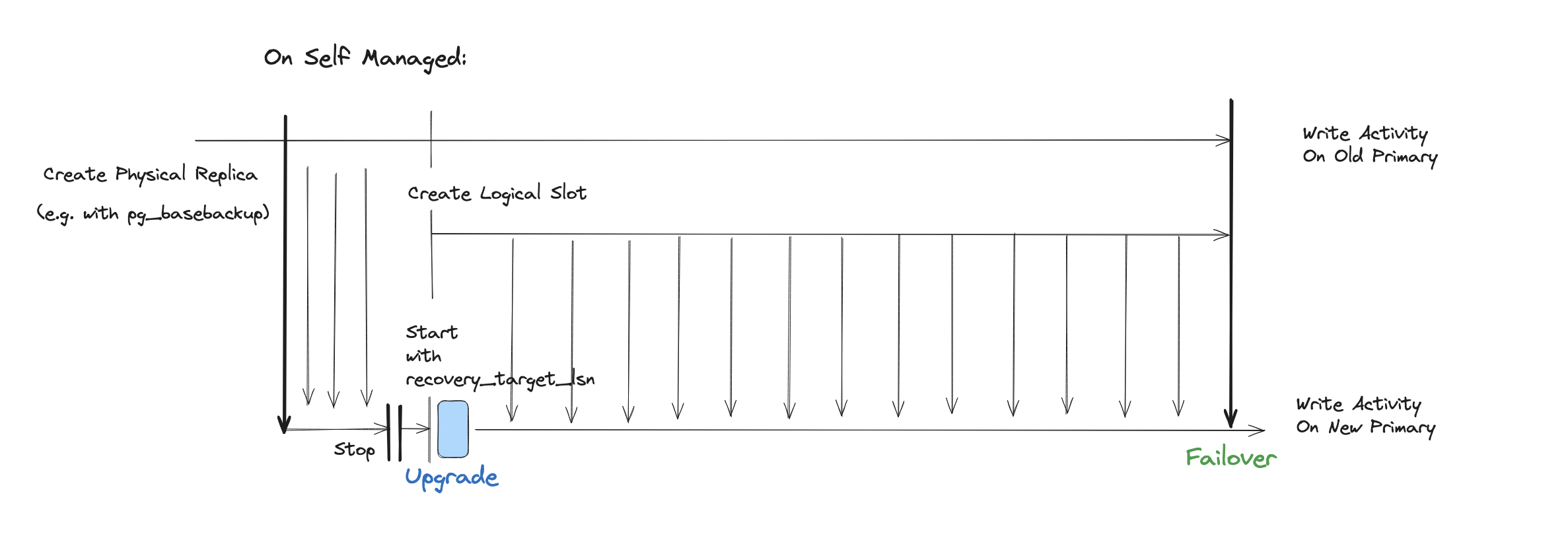
Then you’re stopping that replica and create the logical replication slot on the old primary. You note which LSN number that was created with, because you don’t have a subscriber yet, right? It’s not going to advance. Then you have your replica catch up to the starting point of the logical slot. At that point, you can do the upgrade and then create the subscription and have it follow the logical application stream. That seems like the much better way of solving this problem.
What I really wish is that providers implemented the second approach for us so that we could just reliably use it without having to come up with our own solutions.
Blue green deployments on AWS RDS
Now on that last note, RDS has actually implemented what they call blue green deployments, but it does seem like that’s not necessarily something that I would trust a hundred percent yet.
I personally haven’t used them much, but on the mentioned Hacker News discussion, somebody commented that they recently tried it and ultimately things got stalled and the AWS UI essentially said: Hey, I couldn’t switch over. And so I think this is the kind of thing where sometimes the managed service providers don’t give you enough introspection, enough access to really perform this well, but I hope that we’ll see AWS iterate on this further and other providers like Azure or GCP offer a better way to do major version upgrades as well.
If you liked E95 of 5mins of Postgres, why not subscribe to our YouTube channel, sign up for our newsletter or follow us on LinkedIn and Twitter to get updates about new episodes?
What we have discussed in this episode of 5mins of Postgres
-
Creating a Logical Replica from a Snapshot in RDS Postgres - by Christos Christoudias
-
PostgreSQL Logical Replicas and Snapshots: Proceed Carefully - by Jeremy Schneider
-
Postgres 10 highlight - recovery_target_lsn - by Michael Paquier
-
5mins of Postgres E43: Logical replication in Postgres 15 & why the REPLICA IDENTITY matters