
Efficient Postgres Full Text Search in Django
 By Adeyinka Adegbenro
By Adeyinka AdegbenroIn this article, we’ll take a look at making use of the built-in, natural language based Postgres Full Text Search in Django. Internet users have gotten increasingly discerning when it comes to search. When they type a keyword into your website’s search bar, they expect to find logically ranked results, including related matches and misspellings.
Because users are used to these sophisticated search systems, developers have to build applications that use more than simple LIKE queries.
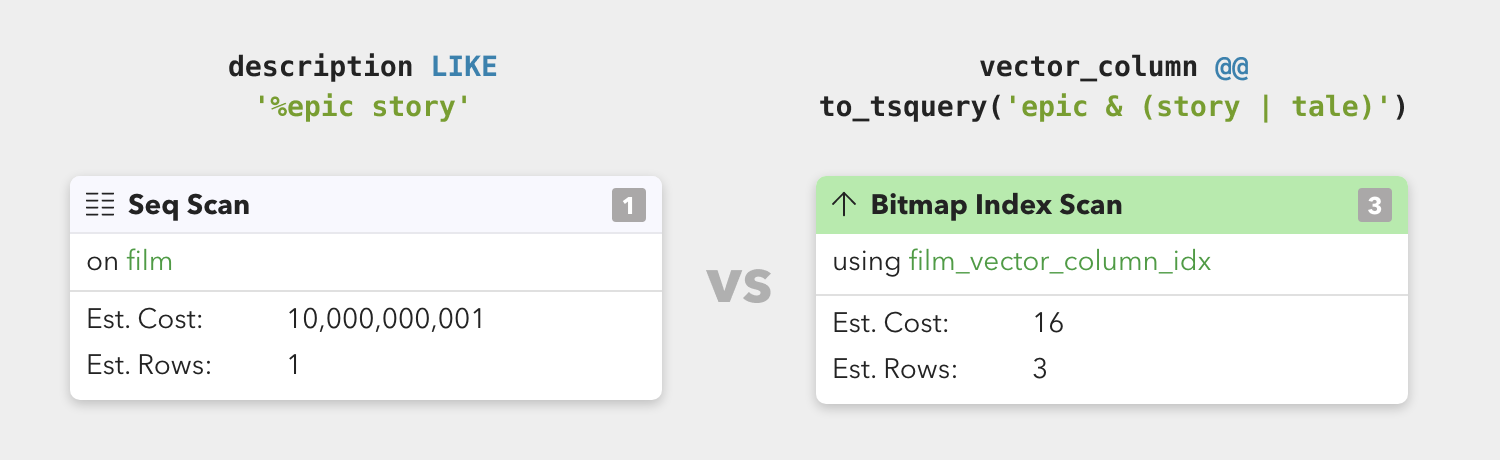
Postgres Full Text Search has been available since Postgres 8.3. It can be used to find records based on semantics and knowledge of the language rather than simple string matching, is very flexible, and unlike other search options such as LIKE, it performs well for partial matches.
While LIKE can be supported by indexes, that usually won’t work well when the % operator is used on the left side of the search term. Typically this means the query planner reverts to sequential scans when using wildcard operators like this:
SELECT title FROM film WHERE description LIKE '%brilliant';
When searching multiple columns, you also have additional effort, as each column needs to be queried separately using LIKE. There are more flexible alternatives, such as SIMILAR TO and POSIX regular expression search, but those are still difficult to use when you want to catch different variations of a word (e.g., word variations like “jump,” “jumps,” “jumped,” and “jumping”).
Because LIKE and other simple methods lack language support and cannot handle word variations or ranking, Postgres Full Text Search (FTS) is generally a better option when implementing search directly in the database. With FTS, your searches will match all instances of the word, its plural, and the word’s various tenses. Because FTS is bundled into Postgres, there’s no need to install extra software and no extra cost for using a third-party search provider. Additionally, all your data are stored in one place, which reduces your web application’s complexity.
This article will show you how to use Full Text Search in raw PostgreSQL queries and implement equivalent queries in Django using the Postgres driver. Along the way, you’ll see some of the use cases for the various Full Text Search methods that Postgres provides.
Should you be interested in learning more about Full Text Search with Rails, please check out our article here: Full Text Search in Milliseconds with Rails and PostgreSQL.
Core Concepts of Postgres Full Text Search
PostgreSQL provides several native functions for Full Text Search. In the following sections, you’ll see how to use them to “vectorize” your results and search queries so that you can use Postgres’s Full Text Search features.
tsvector data type
Before a text or document can be searched using FTS, you need to convert it to an acceptable data type, known as a tsvector. To convert plain text to a tsvector, use the Postgres to_tsvector function. This function reduces the original text to a set of word skeletons known as lexemes.
Lexemes are important because they help match related words. For instance, the words satisfy, satisfying and satisfied would convert to satisfi. This means a search for satisfy will return results containing any of the other terms as well. Stop words such as “a,” “on,” “of,” “you,” “who,” etc. are removed because they appear too frequently to be relevant in searches. The to_tsvector function returns the lexemes, along with a digit that denotes each word’s position in the text.
Note that the output of the function is language-dependent. You should tell PostgreSQL to treat the text as English (or whatever language your results are stored in). To convert the sentence “A Fanciful Documentary of a Frisbee And a Lumberjack who must Chase a Monkey in A Shark Tank” to a tsvector, run the following:
SELECT to_tsvector('english', 'A Fanciful Documentary of a Frisbee And a Lumberjack who must Chase a Monkey in A Shark Tank') AS search;
You’ll see output like the following:
search
----------------------------------------------------------------------
'chase':12 'documentari':3 'fanci':2 'frisbe':6 'lumberjack':9 'monkey':14 'must':11 'shark':17 'tank':18
This shows each word’s root as well as its position in the text. For example, the word fanciful, the second word in the text, has been broken down into the lexeme “fanci”, so you see ’fanci’:2.
tsquery data type
Text search systems have two major components: the text being searched and the keyword being searched for. In the case of FTS, both components must be vectorized. You saw how searchable data is converted to a tsvector in the previous section, so now you’ll see how search terms are vectorized into tsquery values.
Postgres offers functions that will convert text fields to tsquery values such as to_tsquery, plainto_tsquery and phraseto_tsquery. Search terms can also be combined with the & (AND), | (OR), and ! (NOT) operators, and parentheses can be used to group operators and determine their order. to_tsquery converts the search terms to tokens and discards stop words.
The following query:
SELECT to_tsquery('english', 'a & beautifully & very & quickly') AS search;
Returns the lexemes “beauti” and “quick” because “a” and “very” are stop words:
search
----------------------------------------------------------------------
'beauti' & 'quick'
Searching
Now that you know how to create a tsvector from your text data and a tsquery from your search terms, you can perform a full-text search using the @@ operator.
For example, you can run the following query to compare two strings:
SELECT to_tsvector('english', 'John''s performance was found wanting') @@ to_tsquery('english', 'want');
This query returns TRUE, indicating that there was a match: want.
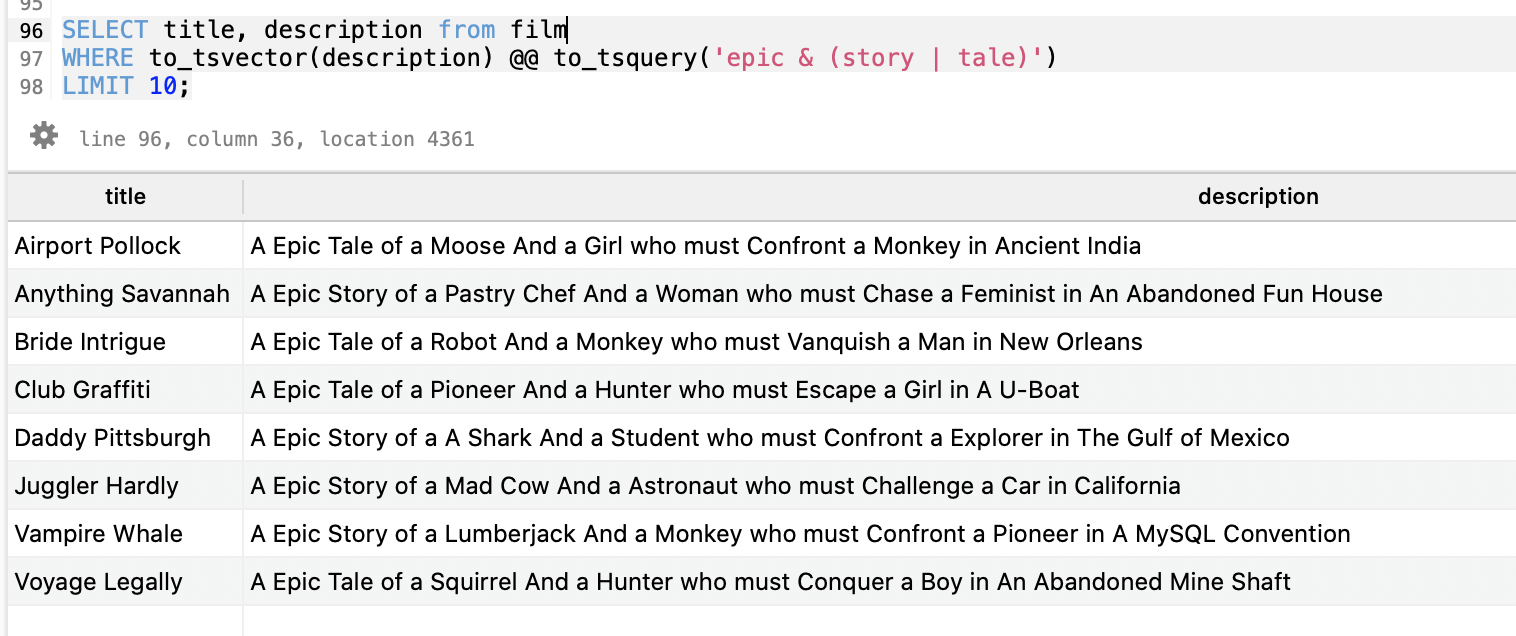
If you had a film table containing movie titles and descriptions, you could use Full Text Search to find all films with a description containing the word epic and either of the words tale or story:
SELECT title, description FROM film
WHERE to_tsvector(description) @@ to_tsquery('epic & (story | tale)')
LIMIT 10;
This would give you results similar to this:
Ranking
Ranking search results can ensure that the most relevant results are shown first. Postgres provides two functions for ranking search results: ts_rank and ts_rankcd. ts_rank considers the frequency of words, while ts_rank_cd (“cd” means “coverage density”) considers the position of search terms within the text being searched.
If you run the following query, you’ll see that rank1 and rank2 are ranked the same (0.06078271) because each search query is found once in the sentence:
SELECT
ts_rank(
to_tsvector('english', 'Dolphins are to water as elephants are to forest'),
to_tsquery('english', 'elephant')
) AS rank1,
ts_rank(
to_tsvector('english', 'Dolphins are to water as elephants are to forest'),
to_tsquery('english', 'dolphin')
) AS rank2;
The more tokens that match the text, the higher the rank. In the following example, rank1 has a higher rank than rank2 because the tokens “elephant” and “dolphin” are both found in the sentence while “snake” is not:
SELECT
ts_rank(
to_tsvector('english', 'Dolphins are to water as elephants are to forest'),
to_tsquery('english', 'elephant & dolphin')
) AS rank1,
ts_rank(
to_tsvector('english', 'Dolphins are to water as elephants are to forest'),
to_tsquery('english', 'dolphin & snake')
) AS rank2;
Weighting
You can also give relevance to some factors over others by weighing them. For instance, when searching the film table, the highest weight could be given to the movie title and less weight could be given to the description using the setweight function:
--- Set the weights
SELECT setweight(to_tsvector('english', 'elephant'), 'A') || setweight(to_tsvector('english', 'dolphin'), 'B') AS weight;
--- Run the query
SELECT
ts_rank(
setweight(to_tsvector('english', 'elephant'), 'A') || setweight(to_tsvector('english', 'dolphin'), 'B'),
to_tsquery('english', 'elephant')
) AS elephant_rank,
ts_rank(
setweight(to_tsvector('english', 'elephant'), 'A') || setweight(to_tsvector('english', 'dolphin'), 'B'),
to_tsquery('english', 'dolphin')
) AS dolphin_rank;
elephant_rank is ranked higher because it matched elephant which has a higher weight of A, compared to dolphin_rank which has a weight of B.
| elephant_rank | dolphin_rank |
|---------------|--------------|
| 0.6079271 | 0.24317084 |
ts_rank takes an optional first argument, weight. When this argument is left empty, it defaults to “1” in the order D, C, B, A. By default, A has the highest weight of 1.0, B has 0.4, C has 0.2, and D has 0.1. You can set the weight of any of A, B, C, or D to a different value using any decimal between -0.1 and 1.0. This allows you to have fine-grained control over how results are returned and ensure that users see the right results for their queries.
Now that you’ve seen how to use Postgres’ Full Text Search functions, you’re ready to start applying these ideas to your Django app.

Using PostgreSQL Full Text Search in Django
Using Postgres’ Full Text Search in Django is an ideal way to add accurate and fast search because it is easy to maintain and fast to work with. To demonstrate Full Text Search in Django, consider a PostgreSQL database dvdrental, with a film table, and an equivalent Film model in a Django application implemented like this:
from django.db import Models
class Film(models.Model):
film_id = models.AutoField(primary_key=True)
title = models.CharField(max_length=255)
description = models.TextField(blank=True, null=True)
def __str__(self):
return ', '.join(['film_id=' + str(self.film_id), 'title=' + self.title, 'description=' + self.description])
In the remainder of this article, you’ll see how to search a single database table field, search multiple fields, rank search results, and optimize the performance of Full text Search using vector fields and indexes. You can run the commands from your Python shell.
Searching a Single field
The simplest way to start using Full Text Search in Django is by using search lookup. To search the description column on the Film model, append __search to the column name when filtering the model:
>>> from <appname>.models import Film
>>> Film.objects.filter(description__search='An epic tale')
<QuerySet [
<Film: film_id=8, title=Airport Pollock, description=A Epic Tale of a Moose And a Girl who must Confront a Monkey in Ancient India>,
<Film: film_id=97, title=Bride Intrigue, description=A Epic Tale of a Robot And a Monkey who must Vanquish a Man in New Orleans>..]>
Under the hood, Django converts the description field to a tsvector and converts the search term to a tsquery. You can check the underlying query to verify this:
>>> connection.queries[0]['sql']
('SELECT "film"."film_id", "film"."title", "film"."description", '
'"film"."release_year", "film"."language_id", "film"."rental_duration", '
'"film"."rental_rate", "film"."length", "film"."replacement_cost", '
'"film"."rating", "film"."last_update", "film"."special_features", '
'"film"."fulltext", "film"."index_column", "film"."vector_column" FROM "film" '
'WHERE to_tsvector(COALESCE("film"."description", \'\')) @@ '
"plainto_tsquery('An epic tale') LIMIT 21")
SearchVector
If you want to use the tsvector on its own, you can use the Django SearchVector class. For example, to search for the term “love” in both the title and description columns, you can run the following in your Python shell:
>>> Film.objects.annotate(search=SearchVector('title', 'description', config='english')).filter(search='love')
<QuerySet [<Film: film_id=374, title=Graffiti Love, description=A Unbelieveable Epistle of a Sumo Wrestler And a Hunter who must Build a Composer in Berlin>,
<Film: film_id=448, title=Idaho Love, description=A Fast-Paced Drama of a Student And a Crocodile who must Meet a Database Administrator in The Outback>,
<Film: film_id=458, title=Indian Love, description=A Insightful Saga of a Mad Scientist And a Mad Scientist who must Kill a Astronaut in An Abandoned Fun House>,
<Film: film_id=511, title=Lawrence Love, description=A Fanciful Yarn of a Database Administrator And a Mad Cow who must Pursue a Womanizer in Berlin>,
<Film: film_id=535, title=Love Suicides, description=A Brilliant Panorama of a Hunter And a Explorer who must Pursue a Dentist in An Abandoned Fun House>,
<Film: film_id=536, title=Lovely Jingle, description=A Fanciful Yarn of a Crocodile And a Forensic Psychologist who must Discover a Crocodile in The Outback>]>
When you inspect the underlying query, you can see how Django uses to_tsvector to query both the title and description fields in the database:
>>> pp(connection.queries[0]['sql'])
('SELECT "film"."film_id", "film"."title", "film"."description", '
'to_tsvector(\'english\'::regconfig, COALESCE("film"."title", \'\') || \' \' '
'|| COALESCE("film"."description", \'\')) AS "search" FROM "film" WHERE '
'to_tsvector(\'english\'::regconfig, COALESCE("film"."title", \'\') || \' \' '
'|| COALESCE("film"."description", \'\')) @@ '
"plainto_tsquery('english'::regconfig, 'love') LIMIT 21")
SearchQuery
SearchQuery is the abstraction of the to_tsquery, plainto_tsquery and phraseto_tsquery functions in Postgres. There are several ways to use the SearchQuery class including using two keywords in a search:
>>> SearchQuery("story beautiful")
Or searching for a specific phrase:
>>> SearchQuery("mad scientist", search_type="phrase")
Unlike SearchVector, SearchQuery supports boolean operators. The boolean operators combine search terms using logic just like they did in Postgres:
>>> SearchQuery("('epic' | 'beautiful' | 'brilliant') & ('tale' | 'story')", search_type="raw")
Using SearchVector and SearchQuery together in a search allows you to create powerful custom searches in Django:
>>> vector = SearchVector('title', 'description', config='english') # search the title and description columns..
>>> query = SearchQuery("('epic' | 'beautiful' | 'brilliant') & ('tale' | 'story')", search_type="raw") # ..with the search term
>>> Film.objects.annotate(search=vector).filter(search=query)
<QuerySet [
<Film: film_id=8, title=Airport Pollock, description=A Epic Tale of a Moose And a Girl who must Confront a Monkey in Ancient India>, <Film: film_id=30, title=Anything Savannah, description=A Epic Story of a Pastry Chef And a Woman who must Chase a Feminist in An Abandoned Fun House>,
<Film: film_id=46, title=Autumn Crow, description=A Beautiful Tale of a Dentist And a Mad Cow who must Battle a Moose in The Sahara Desert>, <Film: film_id=97, title=Bride Intrigue, description=A Epic Tale of a Robot And a Monkey who must Vanquish a Man in New Orleans>,
<Film: film_id=196, title=Cruelty Unforgiven, description=A Brilliant Tale of a Car And a Moose who must Battle a Dentist in Nigeria>,
<Film: film_id=202, title=Daddy Pittsburgh, description=A Epic Story of a A Shark And a Student who must Confront a Explorer in The Gulf of Mexico>...]>
SearchRank
Using SearchVector and SearchQuery to generate Full Text Search queries in Django is a great start, but a robust search feature likely needs custom rankings as well. Search results can be ranked in a Django app using the SearchRank class.
Here’s an example using the default ranking (most matches):
>>> from django.contrib.postgres.search import SearchQuery, SearchRank, SearchVector
>>> vector = SearchVector('title', 'description', config='english')
>>> query = SearchQuery("('epic' | 'beautiful' | 'brilliant') & ('tale' | 'story')", search_type="raw")
>>> Film.objects.annotate(rank=SearchRank(vector, query)).order_by('-rank')
You can also add weights to each field in your SearchVector:
>>> vector = SearchVector('title', weight='A') + SearchVector('description', config='english', weight='B')
>>> query = SearchQuery("('epic' | 'beautiful' | 'brilliant') & ('tale' | 'story')", search_type="raw")
>>> Film.objects.annotate(rank=SearchRank(vector, query)).order_by('-rank')
This makes matches in the title field count more than those in the description.
Optimizing Search Performance in Django
To get the best performance from a Postgres Full Text Search, you need to create an indexed column that can store a tsvector datatype. Performing a search on this new column will be orders of magnitude faster than generating a tsvector with SearchVector on the fly. If the text has been pre-converted and stored in a column, there’s no need for runtime conversion.
Using GIN indexes
To implement this new column in Django, you’ll need to add the SearchVectorField class to the model. To index this field, use a GIN index as recommended for Full Text Search by PostgreSQL.
PostgreSQL provides two main indexes to speed up full text search: GIN (Generalized Inverted Index) and GIST (Generalized Search Tree). The GIST index is faster to build and useful for frequently updated fields, but it can be lossy (i.e. it sometimes returns false positives). GIN is still very scalable, and while it isn’t lossy, it doesn’t allow you to store weights. Learn more about their differences and use cases here.
To add this field and index to a model, use the GinIndex and SearchVectorField classes like this:
from django.db import Models
from django.contrib.postgres.search import SearchVectorField
from django.contrib.postgres.indexes import GinIndex # add the Postgres recommended GIN index
class Film(models.Model):
film_id = models.AutoField(primary_key=True)
title = models.CharField(max_length=255)
description = models.TextField(blank=True, null=True)
vector_column = models.SearchVectorField(null=True) # new field
def __str__(self):
return ', '.join(['film_id=' + str(self.film_id), 'title=' + self.title, 'description=' + self.description])
class Meta
indexes = (GinIndex(fields=["vector_column"]),) # add index
Now, run the migrations for your Django app:
./manage.py makemigrations <your_app_name> && ./manage.py migrate <your_app_name>
Next, you need a way to make sure that anytime the title and description field on the Film table are updated, the vector_column field is automatically computed and stored. For this, you can use PostgreSQL triggers.
Since there’s no way to use triggers in the Django model directly, add a SQL command in a new migration file:
./manage.py makemigrations <your_app_name> -n create_trigger --empty
# Migrations for '<your_app_name>':
# <your_app_name>/migrations/0003_create_trigger.py
Open the auto-generated file and add a trigger set off by the UPDATE command. This trigger computes the vector_column field for new and existing rows:
from django.db import migrations
class Migration(migrations.Migration):
dependencies = [
('<your_app_name>', '0002_auto_20210224_0325'),
]
operations = [
migrations.RunSQL(
sql='''
CREATE TRIGGER vector_column_trigger
BEFORE INSERT OR UPDATE OF title, description, vector_column
ON film
FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(
vector_column, 'pg_catalog.english', title, description
);
UPDATE film SET vector_column = NULL;
''',
reverse_sql = '''
DROP TRIGGER IF EXISTS vector_column_trigger
ON film;
'''
),
]
Run the migrate command for your app again:
python manage.py migrate <your_app_name>
Now your database should have a new column called vector_column that contains an indexed tsvector for each film’s title and description.
Generated Columns in Postgres 12+
Running Postgres 12 or newer? You can make use of the Generated Columns feature to avoid using triggers for updating the tsvector column, by creating the column like this:
ALTER TABLE film ADD COLUMN vector_column tsvector GENERATED ALWAYS AS (
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(description,'')), 'B')
) STORED;
Note that Django does not have official support for generated columns (tagged as “wontfix” in the bug tracker), so you have to create the column manually in a migration:
from django.db import migrations
class Migration(migrations.Migration):
dependencies = [
('<your_app_name>', '0002_auto_20210224_0326'),
]
operations = [
migrations.RunSQL(
sql='''
ALTER TABLE film ADD COLUMN vector_column tsvector GENERATED ALWAYS AS (
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(description,'')), 'B')
) STORED;
''',
reverse_sql = '''
ALTER TABLE film DROP COLUMN vector_column;
'''
),
]
Comparing Query Performance
Now that you have added the new column to optimize performance, you can compare the non-indexed Full Text Search to using the SearchVectorField vector_column. Using your Python shell, import your model and search the title and description without using the vector_column:
>>> from django.db import connection, reset_queries
>>> from <your_app_name>.models import Film
>>> from django.contrib.postgres.search import SearchVector, SearchQuery
>>> from pprint import pprint as pp
>>> vector = SearchVector('title', 'description', config='english')
>>> query = SearchQuery('love')
>>> Film.objects.annotate(search=vector).filter(search=query)
<QuerySet [<Film: film_id=374, title=Graffiti Love, description=A Unbelieveable Epistle of a Sumo Wrestler And a Hunter who must Build a Composer in Berlin>,
...
>>> pp(connection.queries) # Runtime of last run query
[{'sql': 'SELECT "film"."film_id", "film"."title", "film"."description", '
'"film"."vector_column", to_tsvector(\'english\'::regconfig, '
'COALESCE("film"."title", \'\') || \' \' || '
'COALESCE("film"."description", \'\')) AS "search" FROM "film" WHERE '
'to_tsvector(\'english\'::regconfig, COALESCE("film"."title", \'\') '
'|| \' \' || COALESCE("film"."description", \'\')) @@ '
"plainto_tsquery('love') LIMIT 21",
'time': '0.045'}]
>>> reset_queries() # clears time of last query from memory, so we can re-use connection.queries for new queries
As you can see, this query takes 0.045 seconds.
Now, check how long it takes to search against the indexed SearchVectorField vector_column:
>>> Film.objects.filter(vector_column='love')
<QuerySet [<Film: film_id=374, title=Graffiti Love, description=A Unbelieveable Epistle of a Sumo Wrestler And a Hunter who must Build a Composer in Berlin>,
...
>>> pp(connection.queries)
[{'sql': 'SELECT "film"."film_id", "film"."title", "film"."description", '
'"film"."vector_column" FROM "film" WHERE "film"."vector_column" @@ '
"plainto_tsquery('love') LIMIT 21",
'time': '0.001'}]
>>> reset_queries()
On a table with 1,003 rows, query execution time went down from 0.045s to 0.001s!
This could scale up to make a significant difference if you’re dealing with millions of records. The only downside is that saving your data into the new column and indexing it will make writes take slightly longer. Still, this is usually a price worth paying as users expect search to be as fast as possible.
Conclusion
Postgres offers a wide range of tools to support FTS, and in this article, you’ve seen how some of them work. You also saw how to use these tools in a Django application and leverage the SearchVectorField class with a GIN index to optimize performance. While there’s certainly more to building a fast, accurate search application, having a strong understanding of Postgres’ Full Text Search features will help you understand if it’s the best option for you.
Further Reading:
- PostgreSQL Full Text Search Documentation
- Django Full Text Search Documentation
- Full Text Search in Milliseconds with Rails and PostgreSQL
- eBook: Efficient Search in Rails with Postgres
About the Author
Adeyinka works as a Software Engineer at BriteCore, and is based in Lagos, Nigeria. She loves researching and writing in-depth technical content. You can find her on GitHub.