


A look at Postgres 14: Performance and Monitoring Improvements
 By Lukas Fittl
By Lukas FittlThe first beta release of the upcoming Postgres 14 release was made available yesterday. In this article we’ll take a first look at what’s in the beta, with an emphasis on one major performance improvement, as well as three monitoring improvements that caught our attention.
Before we get started, I wanted to highlight what always strikes me as an important unique aspect of Postgres: Compared to most other open-source database systems, Postgres is not the project of a single company, but rather many individuals coming together to work on a new release, year after year. And that includes everyone who tries out the beta releases, and reports bugs to the Postgres project. We hope this post inspires you to do your own testing and benchmarking.
Now, I’m personally most excited about better connection scaling in Postgres 14. For this post we ran a detailed benchmark comparing Postgres 13.3 to 14 beta1 (note that the connection count is log scale):
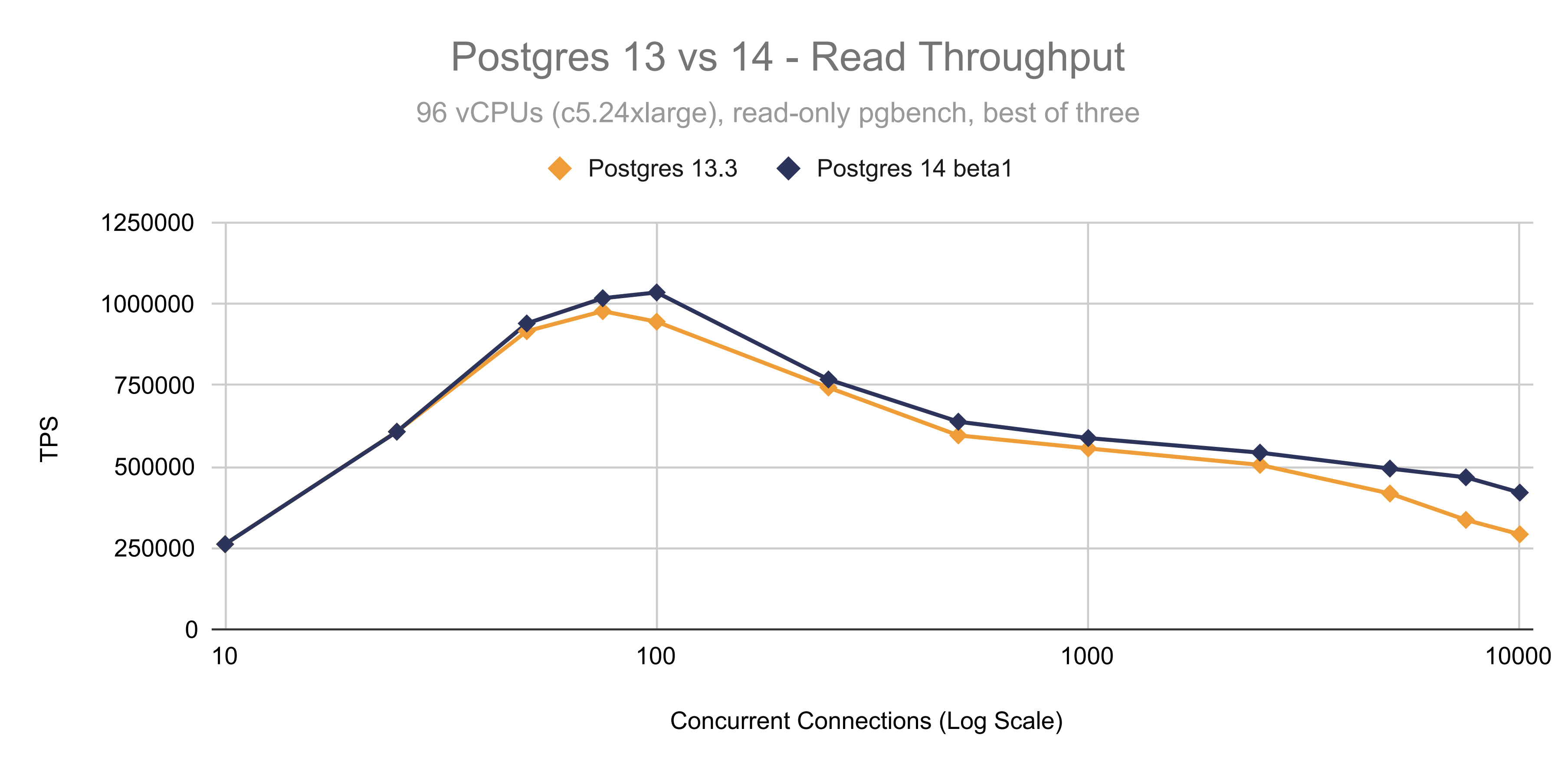
Improved Active and Idle Connection Scaling in Postgres 14
Postgres 14 brings significant improvements for those of us that need a high number of database connections. The Postgres connection model relies on processes instead of threads. This has some important benefits, but it also has overhead at large connection counts. With this new release, scaling active and idle connections has gotten significantly better, and will be a major improvement for the most demanding applications.
For our test, we’ve used two 96 vCore AWS instances (c5.24xlarge), one running Postgres 13.3, and one running Postgres 14 beta1. Both of these use Ubuntu 20.04, with the default system settings, but the Postgres connection limit has been increased to 11,000 connections.
We use pgbench to test connection scaling of active connections. To start, we initialize the database with pgbench scale factor 200:
# Postgres 13.3
$ pgbench -i -s 200
...
done in 127.71 s (drop tables 0.02 s, create tables 0.02 s, client-side generate 81.74 s, vacuum 2.63 s, primary keys 43.30 s).
# Postgres 14 beta1
$ pgbench -i -s 200
...
done in 77.33 s (drop tables 0.02 s, create tables 0.02 s, client-side generate 48.19 s, vacuum 2.70 s, primary keys 26.40 s).
Already here we can see that Postgres 14 does much better in the initial data load.
We now launch read-only pgbench with a varying set of active connections, showing 5,000 concurrent connections as an example of a very active workload:
# Postgres 13.3
$ pgbench -S -c 5000 -j 96 -M prepared -T30
...
tps = 417847.658491 (excluding connections establishing)
# Postgres 14 beta1
$ pgbench -S -c 5000 -j 96 -M prepared -T30
...
tps = 495108.316805 (without initial connection time)
As you can see, the throughput of Postgres 14 at 5000 active connections is about 20% higher. At 10,000 active connections the improvement is 50% over Postgres 13, and at lower connection counts you can also see consistent improvements.
Note that you will usually see a noticeable TPS drop when the number of connections exceeds the number of CPUs, this is most likely due to CPU scheduling overhead, and not a limitation in Postgres itself. Now, most workloads don’t actually have this many active connections, but rather a high number of idle connections.
The original author of this work, Andres Freund, ran a benchmark on the throughput of a single active query, whilst also running 10,000 idle connections. The query went from 15,000 TPS to almost 35,000 TPS - that’s over 2x better than in Postgres 13. You can find all the details in Andres Freund’s original post introducing these improvements.
Dive into memory use with pg_backend_memory_contexts
Have you ever been curious why a certain Postgres connection is taking up a higher amount of memory? With the new pg_backend_memory_contexts view you can take a close look at what exactly is allocated for a given Postgres process.
To start, we can calculate how much memory is used by our current connection in total:
SELECT pg_size_pretty(SUM(used_bytes)) FROM pg_backend_memory_contexts;
pg_size_pretty
----------------
939 kB
(1 row)
Now, let’s dive a bit deeper. When we query the table for the top 5 entries by memory usage, you will notice there is actually a lot of detailed information:
SELECT * FROM pg_backend_memory_contexts ORDER BY used_bytes DESC LIMIT 5;
name | ident | parent | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes
-------------------------+-------+------------------+-------+-------------+---------------+------------+-------------+------------
CacheMemoryContext | | TopMemoryContext | 1 | 524288 | 7 | 64176 | 0 | 460112
Timezones | | TopMemoryContext | 1 | 104120 | 2 | 2616 | 0 | 101504
TopMemoryContext | | | 0 | 68704 | 5 | 13952 | 12 | 54752
WAL record construction | | TopMemoryContext | 1 | 49768 | 2 | 6360 | 0 | 43408
MessageContext | | TopMemoryContext | 1 | 65536 | 4 | 22824 | 0 | 42712
(5 rows)
A memory context in Postgres is a memory region that is used for allocations to support activities such as query planning or query execution. Once Postgres completes work in a context, the whole context can be freed, simplifying memory handling. Through the use of memory contexts the Postgres source actually avoids doing manual free calls for the most part (even though it’s written in C), instead relying on memory contexts to clean up memory in groups. The top memory context here, CacheMemoryContext is used for many long-lived caches in Postgres.
We can illustrate the impact of loading additional tables into a connection by running a query on a new table, and then querying the view again:
SELECT * FROM test3;
SELECT * FROM pg_backend_memory_contexts ORDER BY used_bytes DESC LIMIT 5;
name | ident | parent | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes
-------------------------+-------+------------------+-------+-------------+---------------+------------+-------------+------------
CacheMemoryContext | | TopMemoryContext | 1 | 524288 | 7 | 61680 | 1 | 462608
...
As you can see the new view illustrates that simply having queried a table on this connection will retain about 2kb of memory, even after the query has finished. This caching of table information is done to speed up future queries, but can sometimes cause surprising amounts of memory usage for multi-tenant databases with many different schemas. You can now illustrate such issues easily through this new monitoring view.
If you’d like to access this information for processes other than the current one, you can use the new pg_log_backend_memory_contexts function which will cause the specified process to output its own memory consumption to the Postgres log:
SELECT pg_log_backend_memory_contexts(10377);
LOG: logging memory contexts of PID 10377
STATEMENT: SELECT pg_log_backend_memory_contexts(pg_backend_pid());
LOG: level: 0; TopMemoryContext: 80800 total in 6 blocks; 14432 free (5 chunks); 66368 used
LOG: level: 1; pgstat TabStatusArray lookup hash table: 8192 total in 1 blocks; 1408 free (0 chunks); 6784 used
LOG: level: 1; TopTransactionContext: 8192 total in 1 blocks; 7720 free (1 chunks); 472 used
LOG: level: 1; RowDescriptionContext: 8192 total in 1 blocks; 6880 free (0 chunks); 1312 used
LOG: level: 1; MessageContext: 16384 total in 2 blocks; 5152 free (0 chunks); 11232 used
LOG: level: 1; Operator class cache: 8192 total in 1 blocks; 512 free (0 chunks); 7680 used
LOG: level: 1; smgr relation table: 16384 total in 2 blocks; 4544 free (3 chunks); 11840 used
LOG: level: 1; TransactionAbortContext: 32768 total in 1 blocks; 32504 free (0 chunks); 264 used
...
LOG: level: 1; ErrorContext: 8192 total in 1 blocks; 7928 free (3 chunks); 264 used
LOG: Grand total: 1651920 bytes in 201 blocks; 622360 free (88 chunks); 1029560 used
Track WAL activity with pg_stat_wal
Building on the WAL monitoring capabilities in Postgres 13, the new release brings a new server-wide summary view for WAL information, called pg_stat_wal.
You can use this to monitor WAL writes over time more easily:
SELECT * FROM pg_stat_wal;
-[ RECORD 1 ]----+------------------------------
wal_records | 3334645
wal_fpi | 8480
wal_bytes | 282414530
wal_buffers_full | 799
wal_write | 429769
wal_sync | 428912
wal_write_time | 0
wal_sync_time | 0
stats_reset | 2021-05-21 07:33:22.941452+00
With this new view we can get summary information such as how many Full Page Images (FPI) were written to the WAL, which can give you insights on when Postgres generated a lot of WAL records due to a checkpoint. Secondly, you can use the new wal_buffers_full counter to quickly see when the wal_buffers setting is set too low, which can cause unnecessary I/O that can be prevented by raising wal_buffers to a higher value.
You can also get more details of the I/O impact of WAL writes by enabling the optional track_wal_io_timing setting, which then gives you the exact I/O times for WAL writes, and WAL file syncs to disk. Note this setting can have noticeable overhead, so it’s best turned off (the default) unless needed.

Monitor queries with the built-in Postgres query_id
In a recent survey done by TimescaleDB in March and April 2021, the pg_stat_statements extension was named one of the top three extensions the surveyed user base uses with Postgres. pg_stat_statements is bundled with Postgres, and with Postgres 14 one of the important features of the extensions got merged into core Postgres:
The calculation of the query_id, which uniquely identifies a query, whilst ignoring constant values. Thus, if you run the same query again it will have the same query_id, enabling you to identify workload patterns on the database. Previously this information was only available with pg_stat_statements, which shows aggregate statistics about queries that have finished executing, but now this is available with pg_stat_activity as well as in log files.
First we have to enable the new compute_query_id setting and restart Postgres afterwards:
ALTER SYSTEM SET compute_query_id = 'on';
If you use pg_stat_statements query IDs will be calculated by automatically, through the default compute_query_id setting of auto.
With query IDs enabled, we can look at pg_stat_activity during a pgbench run and see why this is helpful as compared to just looking at query text:
SELECT query, query_id FROM pg_stat_activity WHERE backend_type = 'client backend' LIMIT 5;
query | query_id
------------------------------------------------------------------------+--------------------
UPDATE pgbench_tellers SET tbalance = tbalance + -4416 WHERE tid = 3; | 885704527939071629
UPDATE pgbench_tellers SET tbalance = tbalance + -2979 WHERE tid = 10; | 885704527939071629
UPDATE pgbench_tellers SET tbalance = tbalance + 2560 WHERE tid = 6; | 885704527939071629
UPDATE pgbench_tellers SET tbalance = tbalance + -65 WHERE tid = 7; | 885704527939071629
UPDATE pgbench_tellers SET tbalance = tbalance + -136 WHERE tid = 9; | 885704527939071629
(5 rows)
All of these queries are the same from an application perspective, but their text is slightly different, making it hard to find patterns in the workload. With the query ID however we can clearly identify the number of certain kinds of queries, and assess performance problems more easily. For example, we can group by the query ID to see what’s keeping the database busy:
SELECT COUNT(*), state, query_id FROM pg_stat_activity WHERE backend_type = 'client backend' GROUP BY 2, 3;
count | state | query_id
-------+--------+----------------------
40 | active | 885704527939071629
9 | active | 7660508830961861980
1 | active | -7810315603562552972
1 | active | -3907106720789821134
(4 rows)
When you run this on your own system you may find that the query ID is different from the one shown here. This is due to query IDs being dependent on the internal representation of a Postgres query, which can be architecture dependent, and also considers internal IDs of tables instead of their names.
The query ID information is also available in log_line_prefix through the new %Q option, making it easier to get auto_explain output thats linked to a query:
2021-05-21 08:18:02.949 UTC [7176] [user=postgres,db=postgres,app=pgbench,query=885704527939071629] LOG: duration: 59.827 ms plan:
Query Text: UPDATE pgbench_tellers SET tbalance = tbalance + -1902 WHERE tid = 6;
Update on pgbench_tellers (cost=4.14..8.16 rows=0 width=0) (actual time=59.825..59.826 rows=0 loops=1)
-> Bitmap Heap Scan on pgbench_tellers (cost=4.14..8.16 rows=1 width=10) (actual time=0.009..0.011 rows=1 loops=1)
Recheck Cond: (tid = 6)
Heap Blocks: exact=1
-> Bitmap Index Scan on pgbench_tellers_pkey (cost=0.00..4.14 rows=1 width=0) (actual time=0.003..0.004 rows=1 loops=1)
Index Cond: (tid = 6)
Want to link auto_explain and pg_stat_statements, and can’t wait for Postgres 14?
We built our own open-source query fingerprint mechanism that uniquely identifies queries based on their text. This is used in pganalyze for matching EXPLAIN plans to queries, and you can also use this in your own scripts, with any Postgres version.
And 200+ other improvements in the Postgres 14 release!
These are just some of the many improvements in the new Postgres release. You can find more on what’s new in the release notes, such as:
- The new predefined roles
pg_read_all_data/pg_write_all_datagive global read or write access - Automatic cancellation of long-running queries if the client disconnects
- Vacuum now skips index vacuuming when the number of removable index entries is insignificant
- Per-index information is now included in autovacuum logging output
- Partitions can now be detached in a non-blocking manner with
ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY
And many more. Now is the time to help test!
Download beta1 from the official package repositories, or build it from source. We can all contribute to making Postgres 14 a stable release in a few months from now.
Conclusion
At pganalyze, we’re excited about Postgres 14, and hope this post got you interested as well! Postgres shows again how many small improvements make it a stable, trustworthy database, that is built by the community, for the community.