


Exploring Postgres VACUUM with the VACUUM Simulator
 By Keiko Oda
By Keiko OdaFor many of us, how VACUUM works in Postgres and when autovacuum triggers it is not easy to understand. As you start digging into it, you’ll discover more and more questions. And when you have many tables, it’s hard to keep track of it all.
Luckily, Postgres provides a lot of information that we can use to better understand its internals. For example, we can look at a table’s n_dead_tup value to understand the current number of dead tuples, and relate this to the autovacuum scale factor and threshold to predict when autovacuum will be triggered next. But what if we want to understand the VACUUM schedule over a longer time period?
Today I’m excited to announce a new feature in pganalyze that helps you understand how autovacuum scheduling works for your tables, and how different Postgres settings influence it: The VACUUM Simulator.
Why do we need to VACUUM in Postgres?
Before jumping into the VACUUM Simulator, let’s go over what VACUUM is and why it’s needed. In Postgres, there are all kinds of “garbage” generated due to a detail of its architecture, MVCC. VACUUM is a maintenance process to make this garbage reusable. MVCC, Multiversion Concurrency Control, provides transaction isolation and supports high concurrency with minimal overhead. With this, readers never block writers, and writers never block readers. We will not cover the details of MVCC in this post, but there are many great articles and presentations about MVCC that you can use to learn more.
There are mainly two kinds of garbage in Postgres that VACUUM is cleaning up and making reusable:
- Dead rows (tuples)
- Old transaction IDs
In addition to the above, VACUUM also has other roles, such as updating data statistics (when it’s run with ANALYZE), or updating the visibility map used by index-only scans.
Now we know that VACUUM is literally vacuuming garbage in Postgres. Then, what happens when garbage is left uncleaned? When dead rows are uncleaned, they remain in the database and queries need to do additional I/O (filtering out dead rows only after they’ve been read from disk), resulting in performance degradation. When old transaction IDs are not made reusable, there will be no new transaction ID to issue, resulting in the database refusing writes. Either way, the application won’t be happy with this situation, so it is critical to run VACUUM to prevent these issues from happening.
Let’s look into more details on each kind of garbage for why such things are generated.
Dead rows
When rows are deleted, Postgres doesn’t delete them but marks them as deleted. These deleted rows are called “dead rows”, “dead tuples”, or “dead row versions”. This goes the same with updates as well. Behind the scenes, updates are also “deletes and inserts” in Postgres, therefore these operations also create dead rows.
VACUUM’s job is to make these dead rows reusable. Note that reusable space usually won’t be returned to the OS and will be used for the future INSERTs and UPDATEs on the same table. So even if the table contains lots of dead rows and VACUUM does clean these rows, you may find that it is not decreasing the size of the table. If you want to actually reduce the size of the table, you’ll need to use a tool like pg_repack. You can also run VACUUM FULL to achieve this, but running VACUUM FULL is not recommended and also not practical.
Old Transaction IDs
Transaction ID space in Postgres is finite (32-bit ≈ 4 billion) and old ones need to be reused. In Postgres, every row contains some associated metadata, including information about the transaction ID of the transaction that created it (xmin). Postgres uses this xmin for various things including the MVCC visibility check, so if a specific transaction ID is used in the xmin, that can’t be retired or reused. VACUUM’s job here is to go through all rows in the database and update the row metadata to note that the row has been frozen (i.e., not referenced anymore), making the transaction ID used by that row reusable.
While tables without any activity won’t generate any dead rows and no cleaning is required, these tables still require freezing. As transactions regularly occur within the database, the oldest transaction ID of the table will progressively become older compared to the current transaction ID. Eventually this will run into the transaction space limit.
Autovacuums
We’ve been talking about why VACUUM is needed in Postgres, however, running these manually as needed would be tedious. Postgres provides an autovacuum feature, which will run VACUUM and ANALYZE commands automatically based on a set of predefined parameters (it wasn’t available by default until Postgres 8.3, shipped in 2008). The autovacuum launcher will periodically check if tables need VACUUM or not, and once it detects that a certain table exceeds the threshold, it’ll trigger an autovacuum worker to run VACUUM on that table.
Autovacuum can be triggered by the following 3 causes:
- Triggered by dead rows
- How many dead rows are in the table
- Triggered by freeze age
- How old is the oldest unfrozen transaction ID of the table
- Triggered by inserts (Postgres 13 or above)
- How many rows are inserted since the last VACUUM
Though the overarching goal of autovacuum is to make reusable space from various forms of garbage, each cause directs focus to specific aspects. For instance, the dead rows trigger is explicitly aimed at cleaning up these dead rows, while the freeze age trigger concentrates on freezing old transaction IDs. The insert trigger, new in Postgres 13, primarily updates the visibility map.
Autovacuum also operates in two distinct modes: non-aggressive and aggressive. In non-aggressive mode, the focus is on cleaning up dead rows or updating the visibility map, often without performing freezing. This mode is applied when the age of the oldest unfrozen transaction ID (freeze age) is less than vacuum_freeze_table_age. In contrast, aggressive mode, which is triggered when the freeze age exceeds vacuum_freeze_table_age, primarily performs freezing. The distinction between these modes is particularly relevant for dead row and insert-based autovacuums, as autovacuums triggered by freeze age are always focused on performing freezing.
In essence, while autovacuums triggered by dead rows or inserts aren’t primarily focused on freezing, they can still aid in freezing when operating in aggressive mode. Similarly, autovacuums triggered by freeze age or inserts can also assist in cleaning up dead rows.
VACUUM Simulator for Postgres
Let’s look into each trigger type and its corresponding threshold, exploring how the VACUUM Simulator can provide valuable insights. Through the VACUUM Simulator, you gain access to simulated autovacuum data and observe how VACUUMs are triggered based on the table’s real statistical data. The VACUUM Simulator enables you to understand the interaction between configuration settings (that establish thresholds) and autovacuums triggered by these settings. To access the VACUUM Simulator’s page for a specific table, navigate to the individual table section on the Schema Statistic page, then select the “VACUUM Simulator” tab. If you’re already using pganalyze, I recommend opening the VACUUM Simulator page of a table of your choice and experimenting with the configuration settings as you read through the following sections.
Triggered by dead rows
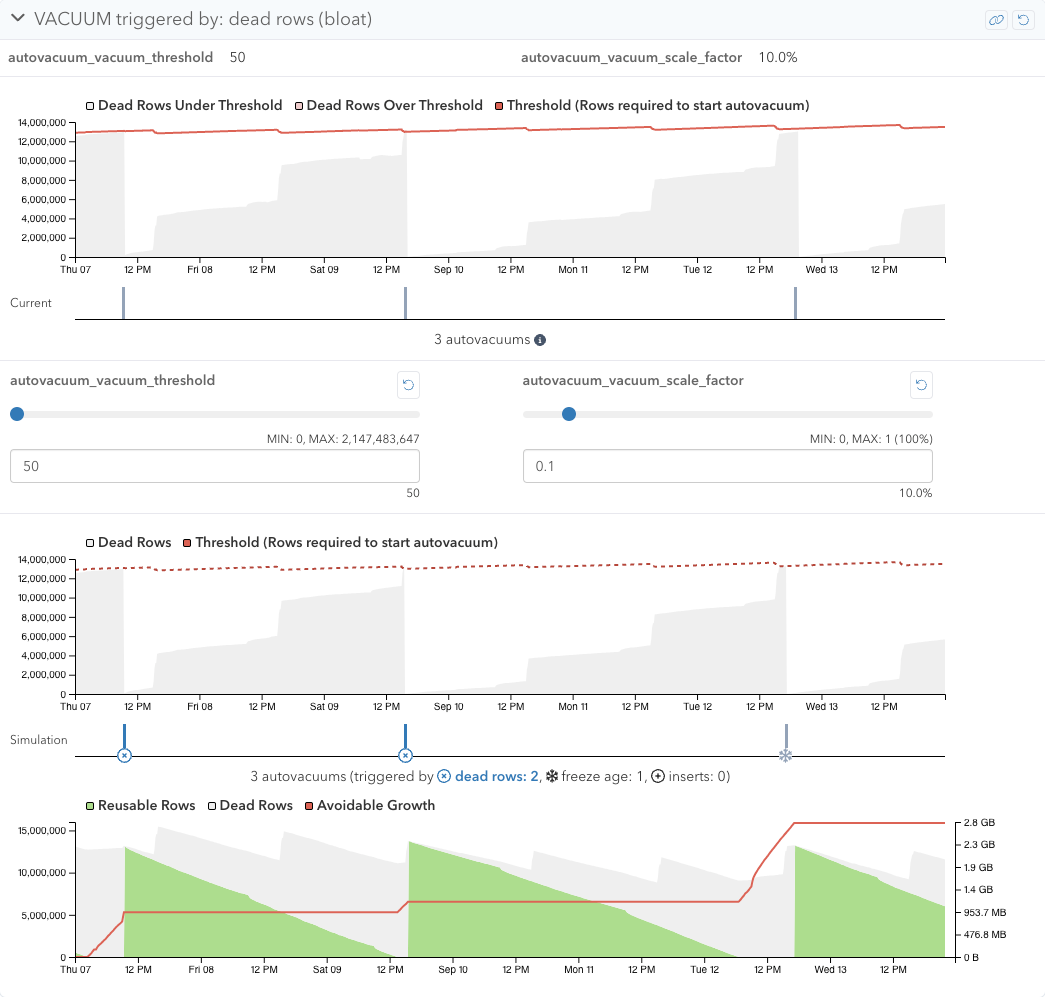
With autovacuums triggered by dead rows, the threshold is defined as the following:
threshold = autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * pg_class.reltuples
where pg_class.reltuples is the number of live rows in the table.
With the VACUUM Simulator, you can tweak autovacuum_vacuum_threshold and autovacuum_vacuum_scale_factor in this section. Lowering these configuration settings usually triggers autovacuums more, as the threshold becomes lower and the dead row count will reach the threshold more often. You can first try lowering autovacuum_vacuum_scale_factor to see how it will affect the behavior, before touching autovacuum_vacuum_threshold.
Triggered by freeze age
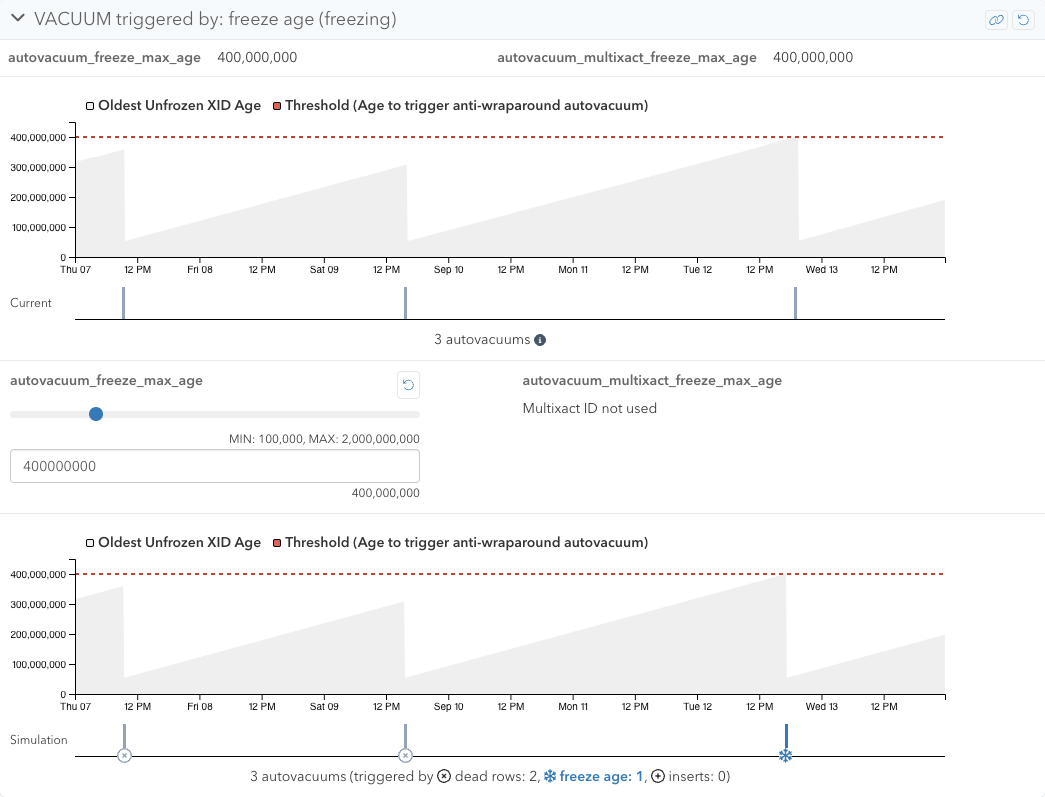
When the age of the oldest unfrozen transaction ID exceeds autovacuum_freeze_max_age, freeze age autovacuums will be triggered. These autovacuums are called anti-wraparound autovacuums. If your database is using multixact IDs, this also applies if the oldest unfrozen multixact ID exceeds autovacuum_multixact_freeze_max_age.
With the VACUUM Simulator, you can tweak autovacuum_freeze_max_age and autovacuum_multixact_freeze_max_age in this section. autovacuum_multixact_freeze_max_age can be only tweaked if multixact IDs are being used in your database. Lowering these configuration settings triggers autovacuums more, and raising these configuration settings triggers autovacuums less.
Triggered by inserts
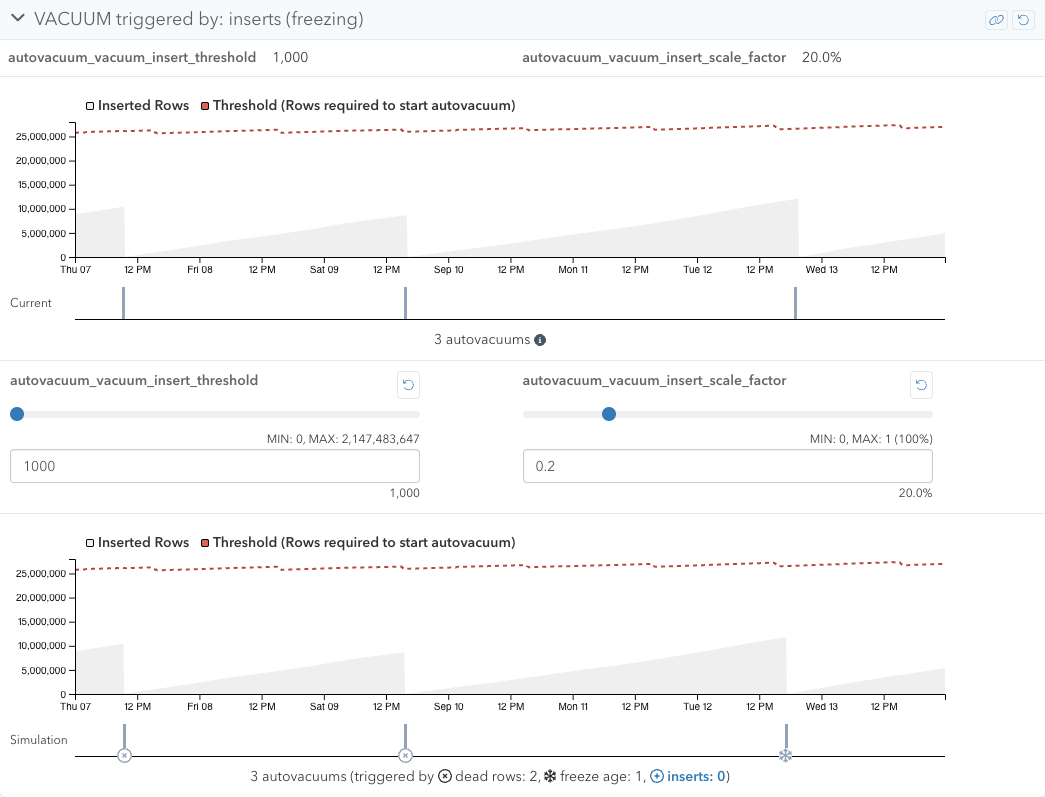
With autovacuums triggered by inserts, autovacuums will be triggered when the number of inserted rows (since the last VACUUM) exceeds the following threshold:
threshold = autovacuum_vacuum_insert_threshold + autovacuum_vacuum_insert_scale_factor * pg_class.reltuples
where pg_class.reltuples is the number of live rows in the table.
With the VACUUM Simulator, you can tweak autovacuum_vacuum_insert_threshold and autovacuum_vacuum_insert_scale_factor in this section. Lowering these configuration settings triggers autovacuums more with append-only or append-mostly tables, though this rarely triggers autovacuums for other types of tables.
If you are observing too many insert-based autovacuums on a table, you can make autovacuum_vacuum_insert_scale_factor 0 and adjust autovacuum_vacuum_insert_threshold to find a reasonable threshold.
Conclusion
We’ve covered the core functions of VACUUM and autovacuums in Postgres, and touched on how the VACUUM Simulator can aid in better understanding these processes. For further insights, our documentation offers extensive resources, including the VACUUM Simulator details. Personally, I frequently return to the documentation’s VACUUM Advisor section, especially What is Freezing?. Returning to the VACUUM Advisor section has really helped me grasp these concepts better.
Creating the VACUUM Simulator was sparked by my efforts to understand VACUUM better while developing the VACUUM Advisor feature launched in July. There is also an open source version of the VACUUM Simulator for educational purposes, which you can access at https://vacuum-simulator.netlify.app/. I recently gave a talk titled “Exploring Postgres VACUUM with the VACUUM Simulator” at PostgreSQL Conference Japan 2023. The talk was in Japanese, but the slides have English subtitles. You can check them out here.
I hope this tool and slides help others as they navigate through VACUUM in Postgres, making it easier to understand and use.