
The Dilemma of the ‘AI DBA’
 By Lukas Fittl
By Lukas FittlLike many in the industry, my perspective on AI tools has shifted considerably over the past year, specifically when it comes to software engineering tasks. Going from “this is nice, but doesn’t really solve complex tasks for me” to “this actually works pretty well for certain use cases.” But the more capable these tools become, the sharper one dilemma gets: you can hand off the work, but an AI agent won’t ultimately be responsible when the database goes down and your app stops working.
For databases, the terms ‘AI DBA’ and ‘self-driving database’ have become marketing buzzwords with the promise of having an agent that can handle creating indexes, optimizing data models, and tuning parameter settings, leaving humans free to focus on higher-value work. The appeal is understandable. Databases are hard; Postgres can behave in odd ways; and, if an agent can absorb that complexity, why invest in becoming an expert yourself?
While I’m a big believer in automating routine tasks, I worry the ‘AI DBA’ discourse is missing the mark in terms of the practical, grounded truth of how to use AI tools effectively, especially in production, and who’s responsible when incidents happen.
If we let the AI do it all willy-nilly, then we accumulate cognitive debt and lose important context, making it harder to take responsibility for the outcome. But there is hope yet: And it comes in the form of enabling engineers, instead of replacing DBAs.
How the ‘AI DBA’ framing gets it wrong
Framing the role of AI in databases as an ‘AI DBA’ makes a critical mistake: it conflates doing the work with owning the outcome. DevOps gave us a useful precedent here. It didn’t remove responsibility from teams: it moved it closer to them. A feature isn’t done when it’s merged: it’s done when it works in production. That same standard should apply to the database: a deployment isn’t done until it performs in production. AI doesn’t change that bar.
Let’s imagine we have a database team today, with titles like “DBA” or “data platform engineer”:

And let’s say our plan here is that we can replace parts of that team with our new ‘AI DBA’ agent, that can do the work in a good enough way, and is available at all times:

But what happens in that scenario if we have the ‘AI DBA’ agent in the picture? Does it magically fix all production problems? Today it would struggle with even having production access in the first place, because giving production credentials to an autonomous AI agent does not absolve you of its decisions.
What LLMs are actually good at
Even if models improve significantly, they are still LLMs. You can’t hold an agent accountable. It needs approvals for high-risk actions. Which means in any realistic scenario, responsibility falls back on either the infrastructure team or the application team — and we’ve just made the handoff murkier.
Worse, framing the problem as ‘nobody wants to do DBA work, so let’s replace the DBA’ sends a clear message to experienced database engineers: your expertise isn’t valued here. And beyond the question of accountability, it creates serious problems in practice.
If we think back to why tools like Claude Code have had such tremendous success over the last year, it’s because it put engineers in the driver’s seat - and made them more effective at what they’re already doing. Quickly cross-referencing different pieces of source code, letting the LLM write code for CRUD tasks, exploring different ways of solving a problem, or investigating production incidents from different data sources effectively, whilst quickly going back to the source.
What does this mean for working with Postgres databases?
Rather than replacing database experts with an AI agent, we should focus on what tasks LLMs genuinely excel at today: Information retrieval across different tools, locating the source code file that produced a query, reviewing pull requests automatically for bad patterns, and providing basic fluency for someone unfamiliar with the database, and apply that focus to enabling engineers who work with databases but whose day-to-day job isn’t the database.
Let’s enable engineers and DBAs to own responsibility for their database
The role of the DBA or data platform engineer needs to change. Successful teams already focus on enabling application engineers, instead of being gatekeepers to changes. The future is specific, purpose-built tools, owned by platform teams, made to be reliable for production use:
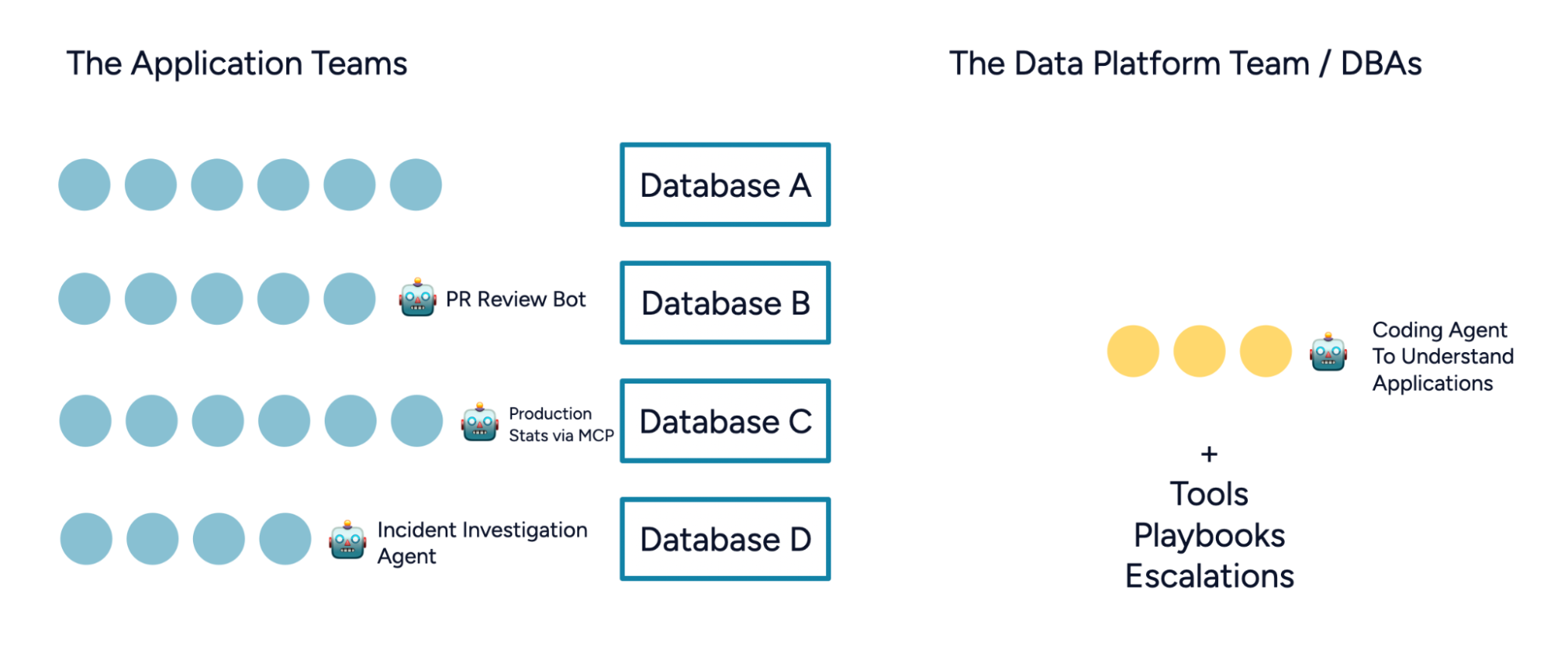
If we get it right, AI tools can help us collect evidence for performance optimizations, so that when the application engineer goes to the data platform team for help, they bring the information necessary to facilitate effective investigative work.
AI tools can also help us bridge the gap in the other direction: data platform engineers can put on the shoes of the application engineer and become familiar with the codebase, by asking things like “Where did this query get called?” or “Does this field get used somewhere?”
To enable organizations to roll out AI tools not just in development, but in production use too, we need to be clear on what is being done - and write code that abstracts production information and possibly actions in a safe way. Whether that means specific tool calls, sandboxing, or providing restricted access via a CLI, it needs to be curated to suit an organization’s environment.
The data platform team should own and provide safe, reliable tools that enable engineers across the organization to use AI tools effectively with production statistics and metadata, and be responsible for their own database.
Looking ahead
At pganalyze we build the best monitoring and optimization tools for Postgres, to enable both engineers and platform teams to work better together. One of the ways we do that is we make sure you have reliable monitoring data about your production system. Which query was running yesterday? What EXPLAIN plan was being used? Did the plan switch unexpectedly?
And it turns out that data is pretty useful when working with AI tools. The pganalyze MCP Server, now in early access, enables safe sharing of specific information about production databases, whilst keeping in mind specific workflows, and enabling engineers to work better.
There is more to come later this year. Our aim is to focus on automating the tedious tasks, whilst staying grounded in what actually works for production systems. Sometimes it makes sense to use an AI tool, and sometimes deterministic logic is the best choice. And I’m excited to keep working with, and hearing from teams what works for them, and discover new best practices together.
With thanks to Maciek Sakrejda, Bison Hubert and Laura Kelso for input and reviews on this article.