
An automatic indexing system for Postgres: How we built the pganalyze Indexing Engine
 By Lukas Fittl
By Lukas FittlIndexing is hard. Most people who have worked with databases will agree that regardless of how you do it, creating the right indexes on your database requires thought and detailed analysis. It’s not something to be taken lightly. If you don’t create the right indexes, your queries will be slow, and if you create too many indexes, your writes on busy tables will be slowed down significantly.
But even if you know how to do it, indexing takes a lot of effort. And this has gotten more complex with the use of microservices (no longer a single place to look for queries), and the continued use of ORMs to generate queries from application logic, hiding the exact details of what kind of queries are running on production.
Over a year ago we set out to challenge the status quo. Our guiding principle was to build a better indexing system that is AI-assisted, but developer-driven. And today we are introducing the first leap forward to help address the complexity of indexing modern query workloads.
In this blog post, we will walk you through the new pganalyze Indexing Engine that gives developers a better way to index their database through automatic index selection. This intelligent system can be explained, understood and (in future iterations) tuned to individual indexing preferences.
Continue reading to take a closer look at what the pganalyze Indexing Engine is, and how we built it. If you are interested in how to use the new functionality in pganalyze, check out our companion blog post about the new version of the pganalyze Index Advisor.
A structured approach for database indexing
Best practices for creating the right indexes haven’t changed much over the years, but the knowledge on how to do it isn’t evenly distributed. If you ask a Postgres expert, they will give you a variant of the advice contained in the Postgres documentation, or excellent third-party resources such as Markus Winand’s “Use The Index, Luke”. If you are a typical application developer, you probably know how to handle single and multi-column B-tree indexes, but find it challenging to reason about other Postgres index types such as GIST and GIN.
To start with, let’s take a look at how we can think about indexes at the high level. Fundamentally, indexes are a variant of a cache. We create an additional data structure within our database to help make queries faster - either by answering the query’s question directly from the index, or by optimizing where to look for in the actual table. The tradeoff is that each added index slows down the writes to the database, as the database has to continue to maintain the index data structure.
Compared to other kinds of caches, with indexes we don’t have to worry about cache consistency - the database takes care of that for us - but that’s exactly what makes index writes expensive: they are guaranteed to be consistent with our regular table writes.
In the pganalyze Indexing Engine we represent this fundamental tradeoff of performance improvement with write overhead with two metrics:
- Cost improvement: How much a potential index would improve query performance, based on the Postgres cost model
- Index Write Overhead: How many additional bytes are written to indexes, compared to the bytes written to the table itself
But before we can decide about this tradeoff, how do we even know which indexes we could create? Typically, you start by looking at the queries you are running. For simple queries this is straightforward, but with complex queries that becomes hard to reason about quickly.
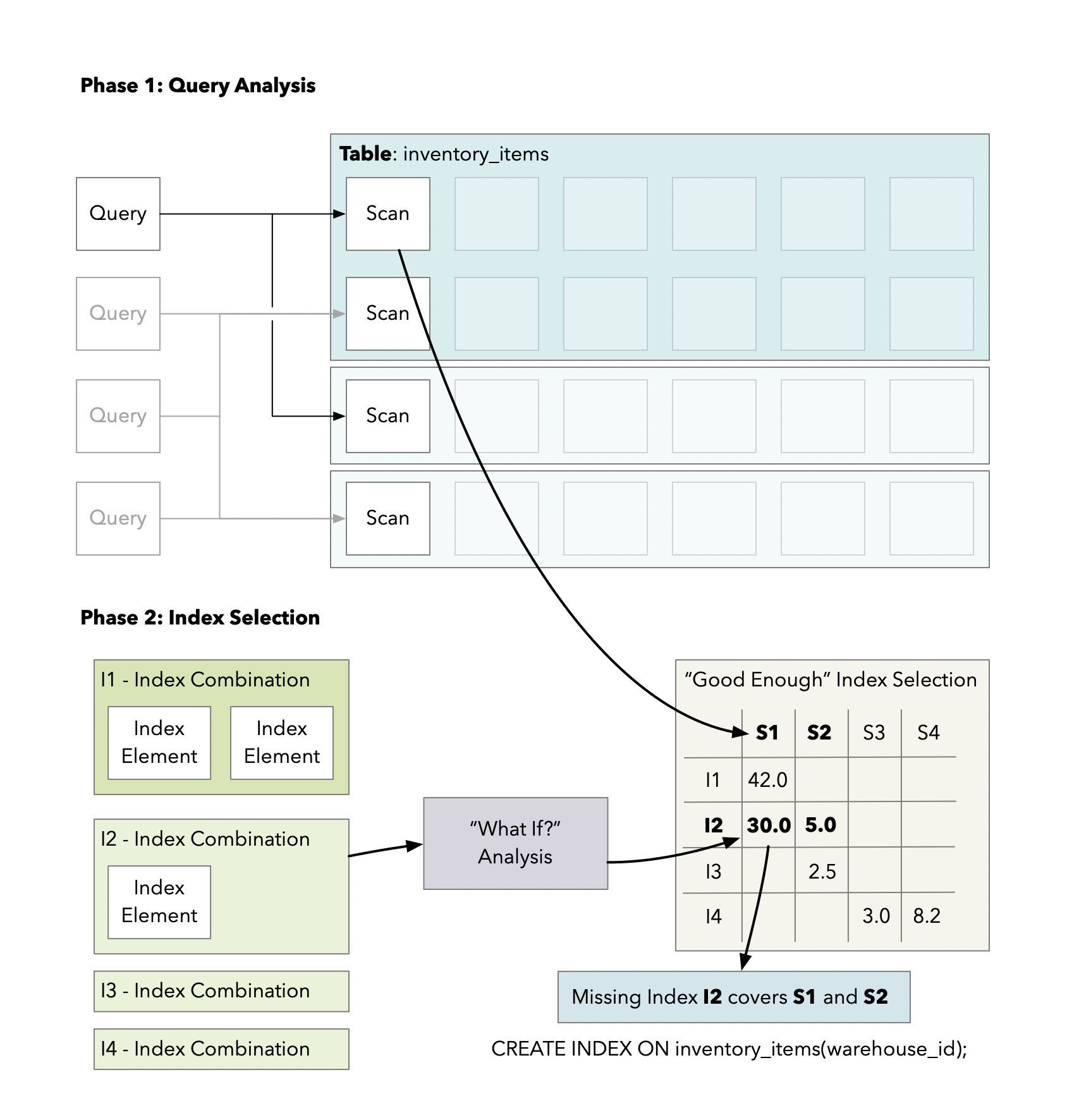
The first phase of the pganalyze Indexing Engine: Query Analysis
The first phase of the Indexing Engine runs at least once for each query (possibly multiple times if the schema changes), and is responsible for making sense of both simple and complex queries.
This phase structures queries into a simpler format for processing by the second phase, and makes it easier to introspect the actual inputs to the index recommendation logic.
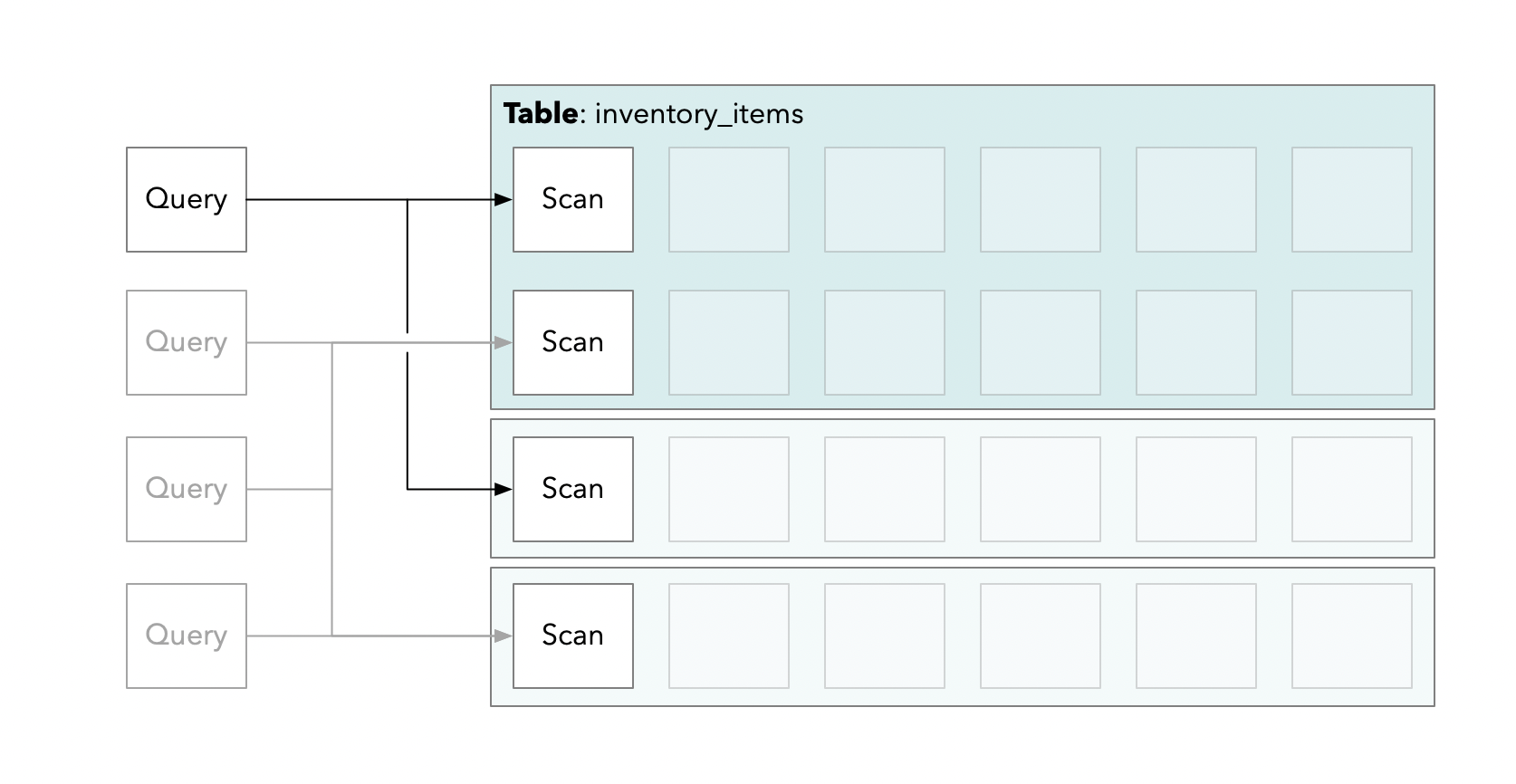
Breaking down Postgres queries into scans
A fundamental decision we’ve made for the pganalyze Indexing Engine is that we break down queries into smaller parts we call “scans”. Scans are always on a single table, and you may be familiar with this concept from reading an EXPLAIN plan. For example, in an EXPLAIN plan you could see a Sequential Scan or Index Scan, both representing a different scan method for the same scan on a given table.
Let’s take a look at an example, that tries to find the top 10 inventory items tagged “milk” that expire next in our California-based warehouses:
SELECT inventory_items.id
FROM warehouses
JOIN inventory_items USING (warehouse_id)
WHERE warehouse.location_state = 'CA'
AND inventory_items.tags @> ARRAY['milk']
ORDER BY inventory_items.expires_at ASC
LIMIT 10
If we separated this into scans, it would look like this:
--- inventory_items scan
SELECT id
FROM inventory_items
WHERE warehouse_id = $n
AND inventory_items.tags @> ARRAY['milk']
ORDER BY inventory_items.expires_at ASC
LIMIT 10;
--- warehouses scan
SELECT warehouse_id
FROM warehouses
WHERE warehouse_id = $n
AND location_state = 'CA'
You’ll note that warehouse_id = $n shows up in both scans. In practice, Postgres will load the data with one of two options:
- Load the data for both tables separately, and then join the data together using a Hash or Merge Join operation (using “warehouse_id” to match up rows)
- Use a Nested Loop, and e.g. load warehouses first, and then run the inventory items scan once for each warehouse, and include the “warehouse_id = $n” filter when loading data
Creating generic query plans from pg_stat_statements queries
Now, how can we go about automating this? In general, we need to look at EXPLAIN plans. But you may not always have an EXPLAIN plan available. Which is why, in the current version of the pganalyze Indexing Engine, we run what’s called a “generic” query plan, and use that to determine whether a JOIN clause is likely to be indexable.
This is powered by a modified version of the Postgres planner that runs as part of the pganalyze app. This modified planner can generate EXPLAIN-like data from just a query and schema information - and most importantly, that means we can take query statistics data from pg_stat_statements and generate a generic query plan from it. You can read more about that in our blog post “How we deconstructed the Postgres planner”.
Let’s take a look at what’s possible with this scan data in the second phase of the Indexing Engine:
The second phase of the Indexing Engine: Index Selection
Once we have broken queries into individual scans for each table, we can now review existing indexes, and come up with index recommendations.
The input into the second phase looks like this, for each table present in the system:
{
"Relation Name": "queries",
"Namespace Name": "public",
"Scans": [
{
"Scan ID": "00000000-0000-0000-0000-000000000001",
"Where Clauses": [
"(queries.database_id = $1)"
],
"Join Clauses": [
"(queries.id = $1)"
],
"Estimated Scans Per Minute": 0.68
},
{
"Scan ID": "00000000-0000-0000-0000-000000000002",
"Where Clauses": [
"(queries.id = $1)"
],
"Join Clauses": [
],
"Estimated Scans Per Minute": 12668.31
},
{
"Scan ID": "00000000-0000-0000-0000-000000000003",
"Where Clauses": [
"(queries.last_occurred_at < CURRENT_DATE)"
],
"Join Clauses": [
],
"Estimated Scans Per Minute": 12248.96
},
The WHERE clauses in this input is what you would commonly see in the WHERE clause part of a query. JOIN Clauses on the other hand are conditions that are typically seen in the JOIN clause of a query. This set of clauses is already filtered to only contain clauses that are likely usable as part of a parameterized Index Scan (i.e. as the inner relation of a Nested Loop). This separation between JOIN and WHERE was done as part of query analysis, to help the Indexing Engine decide which clauses are always usable, vs which may require further checks.
Additionally, schema information is provided like this, with special config variables to set the Postgres table statistics:
CREATE EXTENSION IF NOT EXISTS btree_gist;
CREATE SCHEMA IF NOT EXISTS public;
CREATE TABLE public.queries (
id bigint NOT NULL,
database_id integer NOT NULL,
last_occurred_at date,
--- …
PRIMARY KEY (id)
);
CREATE INDEX index_queries_on_database_id ON public.queries USING btree (database_id);
SET pganalyze.curpages.public.queries = 1234;
SET pganalyze.relpages.public.queries = 1234;
SET pganalyze.reltuples.public.queries = 5678;
SET pganalyze.null_frac.public.databases.database_id = 0.0;
SET pganalyze.avg_width.public.schema_columns.database_id = 8;
SET pganalyze.n_distinct.public.schema_columns.database_id = 100.0;
SET pganalyze.correlation.public.schema_columns.database_id = 0.02;
--- …
You can see that column-level statistics are included as well, to help the Indexing Engine make decisions which columns to prioritize.
Future versions of the Indexing Engine will provide options to include additional input parameters, specifically to use typical bind parameter values to improve selectivity estimates for clauses, as well as provide details on extended statistics, if available.
Extracting index element candidates
The next step involves turning the list of scans into potential candidates for index elements. Index elements are what you could also call the “columns” of an index, i.e., a list of table columns or expressions being indexed.
In this step we utilize the Postgres planner to tell us which operator classes are applicable for indexing a given clause. For example, the operators present in the above example (< and =) are both indexable by B-Tree indexes in Postgres. You may also have clauses that use operators that are only indexable by other index types. For example, the query previously shown had a clause inventory_items.tags @> ARRAY['milk'], and @> is an operator that’s only indexable with a GIN index.
In addition to remembering the potential index element to be used in an index, we also remember whether the operator was an equality operator (important for B-Tree column ordering), as well as the clause selectivity and number of distinct values in the referenced column.
You could simply index all potential index element candidates as their own single column indexes. But that would not be effective - what we need is to make a decision on which multi-column combinations to generate.
Generating multi-column index combinations
When the Indexing Engine processes the scan list, it doesn’t just extract the individual index elements. It also generates a list of potential combinations of these elements to allow consideration of multi-column index options. Multi-column indexes have two primary benefits:
- They allow a single index to provide a more selective answer, without having to resort to a BitmapAnd operation that combines multiple indexes
- They allow use of the same index by multiple queries with different clauses (in some cases)
Adding more columns to an index increases its Index Write Overhead, as more data needs to be stored in the index. (You can read more details about Index Write Overhead in our documentation.) We avoid recommending a multi-column index when a single column index is good enough, but more about that in a bit.
To assess the best multi-column choice, we generate all different permutations of index elements for each index. We then sort the index elements based on a special set of rules, to make it most effective for each index type:
-
B-Tree: Lead with index elements referenced in a clause through an equality operator (e.g. “col = $1”), followed by all other elements. Within that set of elements, sort by selectivity (more selective parameters are ordered first).
-
GIST: Sort elements by number of distinct values in the table (more distinct elements are ordered first).
Note that we are still fine tuning the GIST recommendation logic, as well as other indexing types such as GIN (which are not yet available with the Indexing Engine).
Once we have the different combinations worth testing out, we go and try them.
”What If?” Analysis
When you read “What If?” you might be thinking we are referring to a certain animated superhero series - but we are in fact referencing an essential aspect of how the pganalyze Indexing Engine is built. “What If?” analysis is what you would typically consider an integral part of any algorithmic optimization logic. It’s the part where the algorithm asks the system it’s observing to tell it what happens if a certain condition is true. And in the case of index selection, it’s where we ask the database how it thinks a particular index would perform.
This has historically been a big challenge for optimizing index selection, as described in a 2020 paper by a team of researchers at Hasso Plattner Institute:
Most of the runtime of what-if based index selection algorithms is usually not spent on the algorithm logic, but on cost estimation calls to the what-if optimizer. Usually, algorithms request a cost estimate for a particular query and a given index combination from the (what-if) opti- mizer. These requests are expensive, …
- Jan Kossmann, Stefan Halfpap, Marcel Jankrift, and Rainer Schlosser, “Magic mirror in my hand, which is the best in the land? An Experimental Evaluation of Index Selection Algorithms”
The most popular option to do this for Postgres is HypoPG, created by Julien Rouhaud. HypoPG is an extension for Postgres that allows creating hypothetical indexes on your production system, and then lets you run EXPLAIN with the hypothetical index taken into account.
However, we found that in our specific context, a more purpose built solution is a better fit, that runs solely within the pganalyze system. Our solution for “What if?” analysis is built on the Postgres planner, and runs directly within the pganalyze app, requiring no extensions on the production database, and zero overhead for running “What if?” calls (as they are all run within the pganalyze app, separate from the database).
This approach also allows us to add extra instrumentation that allows the Indexing Engine to compare all possible indexes for a given scan, not just the best one.
The result of the “What if?” analysis is a set of cost improvement numbers - one number per scan and index combination.
The “Good Enough” index selection algorithm
Finally, the most important decision: Which index should we pick?
Overall, the pganalyze Indexing Engine looks at index selection as a set covering problem, with the goal of covering all scans on the table with an index that is within 50% of the best possible index.
The “Good Enough” index selection algorithm takes the set of potential indexes, as well as the set of scans, and their potential cost improvements, and produces zero or more index recommendations for a given table.
Elimination of worst candidates
Before we run through the set covering algorithm that selects the indexes to use, we first eliminate all indexes from consideration for a scan that are not within 50% of the best possible result.
This early reduction enables later stages of the algorithm to view this as a greedy set covering problem - any index that remains after this initial elimination would be acceptable and “good enough”.
The index/scan matrix
Let’s take a slightly more complex example from a real world use case.
This matrix represents the results of the “What If?” analysis for a set of 4 existing indexes, 14 possible new indexes and 15 scans:
| S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9 | S10 | S11 | S12 | S13 | S14 | S15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X1 | XXX | XXX | XXX | ||||||||||||
| X2 | |||||||||||||||
| X3 | XXX | XXX | |||||||||||||
| X4 | (x) | (x) | XXX | (x) | (x) | (x) | XXX | XXX | XXX | (x) | |||||
| I1 (0.11) | |||||||||||||||
| I2 (0.14) | 68.1 | ||||||||||||||
| I3 (0.15) | 68.1 | ||||||||||||||
| I4 (0.10) | |||||||||||||||
| I5 (0.08) | |||||||||||||||
| I6 (0.09) | 43.3 | ||||||||||||||
| I7 (0.13) | 77.6 | ||||||||||||||
| I8 (0.12) | 77.6 | ||||||||||||||
| I9 (0.14) | 31.1 | 42.7 | 31.1 | 31.1 | 31.1 | ||||||||||
| I10 (0.15) | 46.1 | 44.3 | 46.1 | 46.1 | 46.1 | ||||||||||
| I11 (0.08) | 63.3 | 46.1 | 68.1 | 46.1 | 63.3 | ||||||||||
| I12 (0.09) | 63.3 | 46.1 | 68.1 | 46.1 | 63.3 | ||||||||||
| I13 (0.16) | 63.3 | 46.1 | 68.1 | 46.1 | 63.3 | ||||||||||
| I14 (0.17) | 63.3 | 46.1 | 68.1 | 46.1 | 63.3 |
You can think of X.. and I.. being mapped to an index like CREATE INDEX possible_index_1 ON table USING btree (some_column).
You can think of S.. being mapped to a scan like SELECT * FROM table WHERE some_column = $1.
Each cell for a potential index (I..) represents the cost improvement over the current baseline (either a SeqScan or existing sub-optimal Index Scan).
Each cell for an existing index (X..) shows “XXX” for indexes that are the best overall, and “(x)” for other existing indexes that match the scan.
Some columns have no cost improvements, typically you will see this when the existing indexes are covering the scan sufficiently.
You can see the calculated Index Write Overhead for each potential index in parenthesis (e.g. I11 has 0.08 Index Write Overhead).
Note that cells that are not within 50% of the best possible improvement (e.g. S1/I2, S1/I5 and I8/I6) have already been marked as not being “good enough” and are shown crossed out.
Set covering algorithm
Based on this input, the Indexing Engine runs a greedy Set Covering Algorithm to determine one or more “good enough” indexes.
It starts with the potential index that matches the most scans, and continues this until all scans are covered. If two indexes match the same number of scans, the index with the lower Index Write Overhead is chosen.
In above example matrix, the algorithm picks as following:
- I11 (covers S2, S5, S10, S11, S15, and has lower write overhead compared to I9,I10,I12,I13,I14)
- I9 (covers S6, S12, S14 — note that S5 and S11 are no longer counted since I11 covers them)
- I6 (covers S1)
- I2 (covers S8)
This result is deterministic. When the algorithm runs again with the same inputs, it would produce the same outcome.
These recommendations are then shown in the Index Advisor for your assessment, benchmarking and, if they are a good fit, for applying them to production
Human review is encouraged. For example, you may choose not to create I2 and I6 in this example, if they represent infrequent queries where you find a sequential scan acceptable.
Conclusion
As you can see, the pganalyze Indexing Engine at its core is a purpose-built optimization system that processes your query workload in multiple steps to come up with a set of recommendations. It is not a machine learning based system, but rather a deterministic, repeatable process. Our goal with the pganalyze Indexing Engine is that you can understand the logic, introspect it, and trust its repeatability.
In our own testing, and in testing with early access customers, the pganalyze Indexing Engine represents a significant leap forward. No longer do we need to look at hundreds or even thousands of queries manually - instead we can let the Indexing Engine digest the information, and present us a recommendation to try out.
We believe that the pganalyze Indexing Engine will become the basis for implementing automation workflows for indexing your Postgres database. Indexing is not a problem that should be left to an AI system to do completely on its own, without interaction. Instead, indexing should be AI-assisted, but developer-driven.
To try out the pganalyze Indexing Engine, you can go into the pganalyze app and use the pganalyze Index Advisor - the recommendations in the new version of the Index Advisor are powered by the Indexing Engine.
Thinking of building something with the pganalyze Indexing Engine? We are working on an API for the Indexing Engine, and would love to hear from you.
Share this article: If you want to share this article with you peers, you can tweet about it here
See a behind-the-scences on the Indexing Engine and Index Advisor in our webinar re-run

On June 16th, 2022, we hosted a webinar and walked through our approach for creating the best Postgres indexes, and our thinking behind the new pganalyze Indexing Engine.
You can watch the webinar here: Webinar Re-Run: How to reason about indexing your Postgres database.