


A balanced approach to automatic Postgres indexing: The new version of the pganalyze Index Advisor
 By Jens Nikolaus
By Jens NikolausHistorically, index creation, tuning and maintenance has been the task of database administrators who had a detailed understanding of the different queries used by applications. The fast-moving pace of modern application development, combined with a move to the cloud, has shifted the responsibility of indexing to application developers - without giving them the right tools.
Application developers today spend a lot of time manually creating indexes for their Postgres queries, reviewing database statistics to find unused indexes, and fine tuning the overall set of indexes for their query workload. This takes a tremendous amount of attention away from what truly matters: Building high-quality software, and developing new application functionality.
Today we are excited to announce the next evolution of the pganalyze Index Advisor that recommends indexes across queries for your whole database, built on the new pganalyze Indexing Engine. As part of the new Indexing Engine, pganalyze is able to predict how the Postgres query planner will evaluate a set of multiple queries, try out hundreds of index combinations, and can make recommendations for missing indexes using its unique “What if?” analysis, with zero overhead on the production database.
Thanks to our ongoing collaboration with customers in early access, we were able to test and iterate on the new pganalyze Index Advisor with real-world data.
“The Index Advisor watches our databases for missing indexes and notifies us about new opportunities for performance optimizations without us having to test hundreds of queries manually. Since we started using pganalyze Index Advisor, we have been able to identify missed index opportunities a lot easier leading to some significant improvements in performance.”
- Gareth Warwick at Auto Trader UK
Let’s take a closer look:
Introducing the pganalyze Indexing Engine
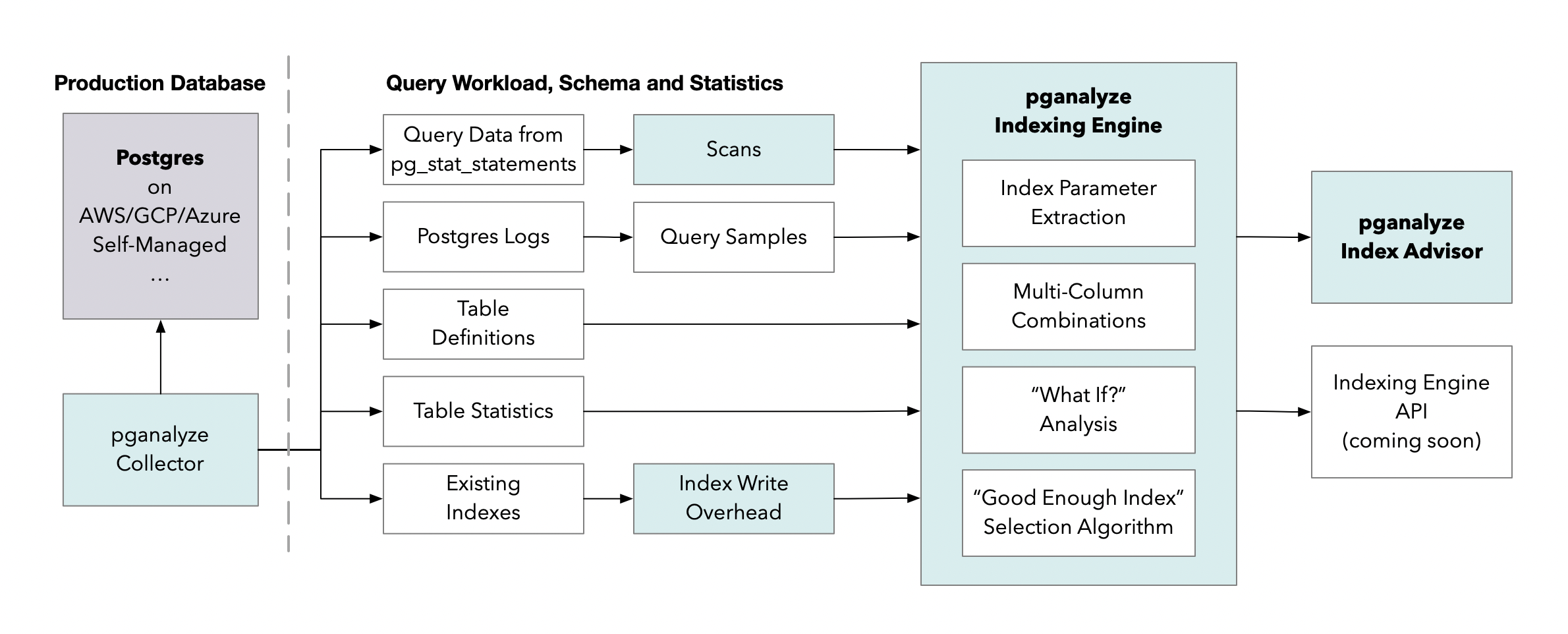
The new Index Advisor is powered by our new pganalyze Indexing Engine for Postgres. When optimizing indexes for your database, we follow a three step approach:
- Break down your query workload into individual scans per table
- Let the pganalyze Indexing Engine assess each table to determine the optimal index configuration
- Surface recommendations from the pganalyze Indexing Engine together with query and table statistics in the interface using the pganalyze Index Advisor
The pganalyze Indexing Engine is built on our unique “What if?” analysis, that allows fast assessment of potential indexes, and how they affect the query workload, see more in our technical blog post by our founder Lukas Fittl: An automatic indexing system for Postgres: How we built the pganalyze Indexing Engine.
Additionally, if you are interested in diving even deeper, feel free to learn more in our pganalyze Indexing Engine documentation
All of this runs completely within the pganalyze application, separate from your production database. You do not need to install any special extensions, and we can do this analysis without access to your table data, instead building on Postgres table statistics.
Next, let’s see how the new pganalyze Index Advisor surfaces recommendations from the pganalyze Indexing Engine:
The next evolution of the pganalyze Index Advisor
The motivation behind the new Index Advisor is to help you efficiently understand and reason about your Postgres query workload and its index opportunities. We aim to provide a service that can do a lot of heavylifting for you when it comes to surfacing performance improvement opportunities. Where possible, we take over as much as possible for you, where it makes sense though we are guiding you towards solutions by providing context and education around Postgres-specific information.
Let’s have a look at the set of features that we make available to you in the pganalyze Index Advisor.
Get an overview of your indexing opportunities
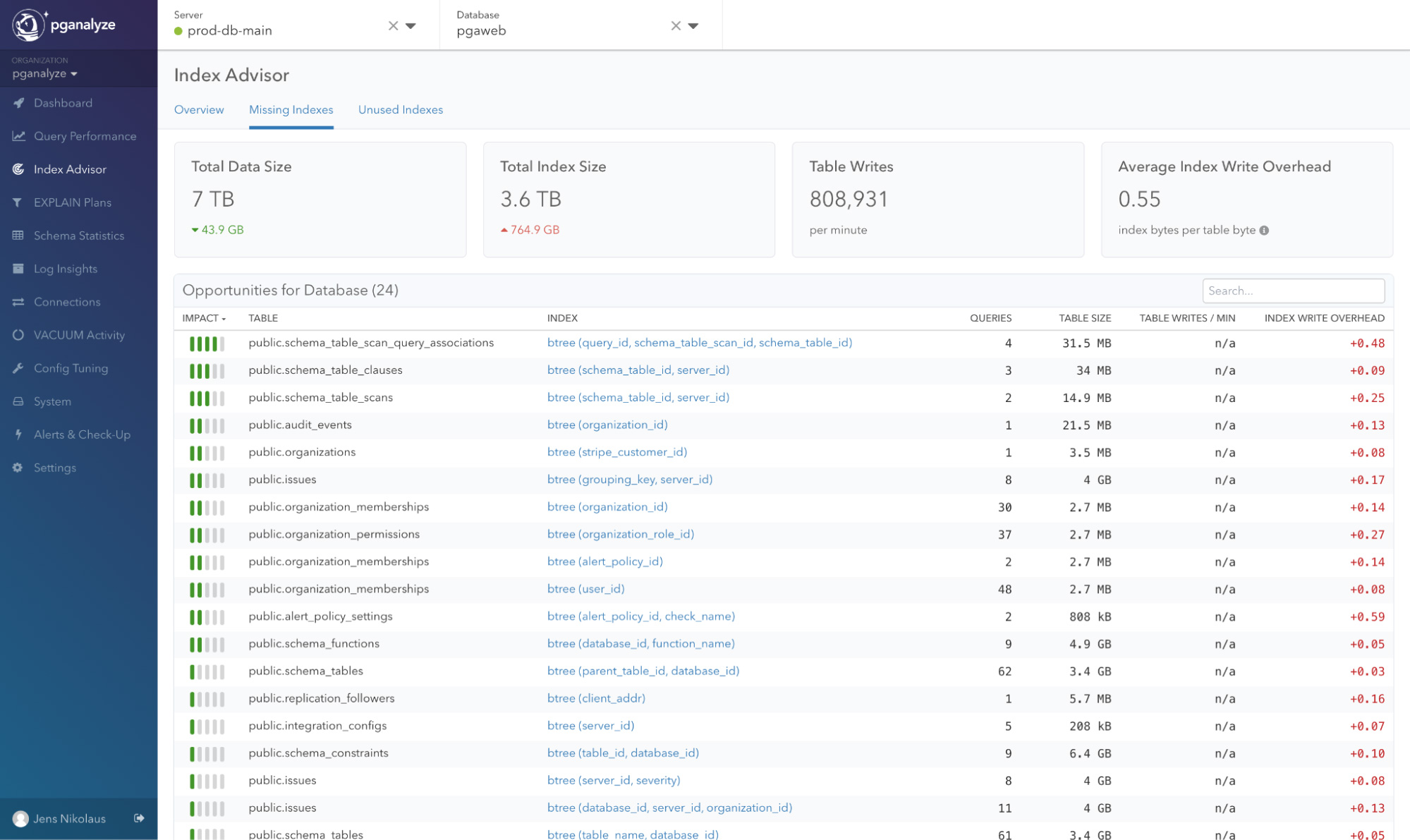
Overview of missing index opportunities
We are introducing a new view into your database that focuses on surfacing missing and unused index opportunities to you. By default, we sort opportunities by overall impact on the database. You can sort by other attributes as well, depending on the type of opportunity you are looking at. As a result, you no longer have to navigate through query pages to look for index opportunities, although you can still do that.
Compared to the previous Index Advisor, our new logic dramatically reduces noise, in terms of the number of opportunities we will surface per database, as we no longer analyze single queries separately but include database statistics and existing indexes in our recommendations.
Understand Index Write Overhead on your database
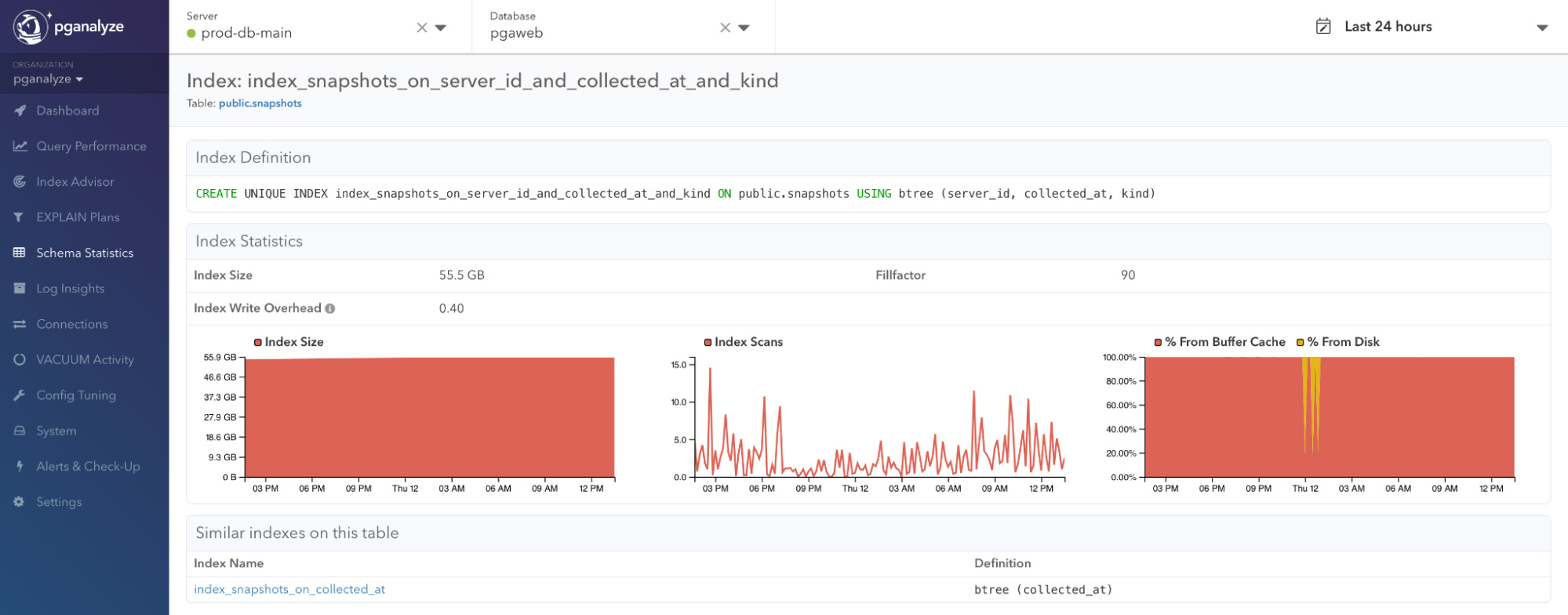
Understand the cost of maintaining existing and proposed indexes with the Index Write Overhead metric
To convey the cost of maintaining existing and proposed indexes, we define the Index Write Overhead metric to estimate the I/O impact of maintaining that index. This metric can guide you to consolidate and drop little-used indexes to have more I/O headroom.
We calculate an estimate of maintaining indexes in your database as a proportion of writes to tables. Specifically, for every byte written to a table in this database, this many bytes are written to its indexes. Here is an example of how Index Write Overhead is calculated. Let’s assume we have a table customers and an index customer_organization_id_idx:
CREATE TABLE customers (
id bigserial PRIMARY KEY,
name text,
organization_id bigint
);
CREATE INDEX customer_organization_id_idx ON customers (organization_id);
We first calculate the size of the average table row, and the index rows:
table_row = \
23 + # Heap tuple header
4 + # Heap item ID
4 + # size of bigserial
50 + # avg_width of text
4 # size of bigint
=> 85 # bytes
btree_index_entry = \
8 + # Index entry header
4 # size of bigint
=> 12 # bytes
Index write overhead is simply the expected average index row size, divided by the expected average table row size, or “0.14” in this case (12.0 / 85.0). You can think of this as saying “for 1 byte of table data, we will write 0.14 bytes to the index”.
We also apply additional correction factors based on HOT updates, and index selectivity, not shown here. We currently do not take other details into account such as the size of the upper pages in a B-tree index (usually a few % of the overall index), or other optimizations such as B-tree deduplication added in Postgres 13.
When Index Write Overhead is shown in the Index Advisor overview, it’s summarized as a weighted average across all tables, weighted by average table writes per minute. This gives you the “typical” index write overhead when a single table write occurs on your database.
You might wonder how we can calculate these kinds of estimates. We wrote about this in a previous blog post on our blog where we explain how we deconstructed the Postgres planner to find indexing opportunities.
Aggregating table scans
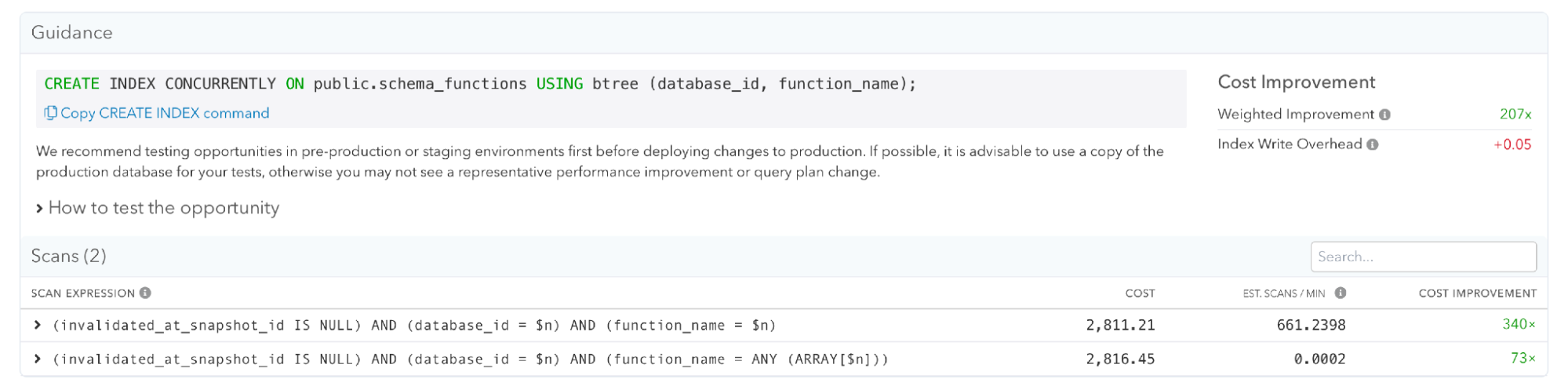
Scans list on the pganalyze Index Advisor opportunity page
On both specific index opportunities and the table and query pages, you will see a new section called “Scans”. Each scan has an associated estimated cost that is averaged across all queries it is referenced in. For more information about how this works, read our documentation here.
Here is how you would reason about what you see see on the Scans list on the Index Advisor opportunity page:
Each scan expression includes information about
- the current cost,
- estimated scans per minute,
- and weighted cost improvement if you were to apply the recommendation.
Cost improvements are expressed as a multiplier, for example, 1.2x faster than the old estimated cost—the table sorts by cost improvement.
If you have been using the Index Check feature to find indexes that are not used by a query, we included it in the new Index Advisor on query pages.
Reason about missing index opportunities
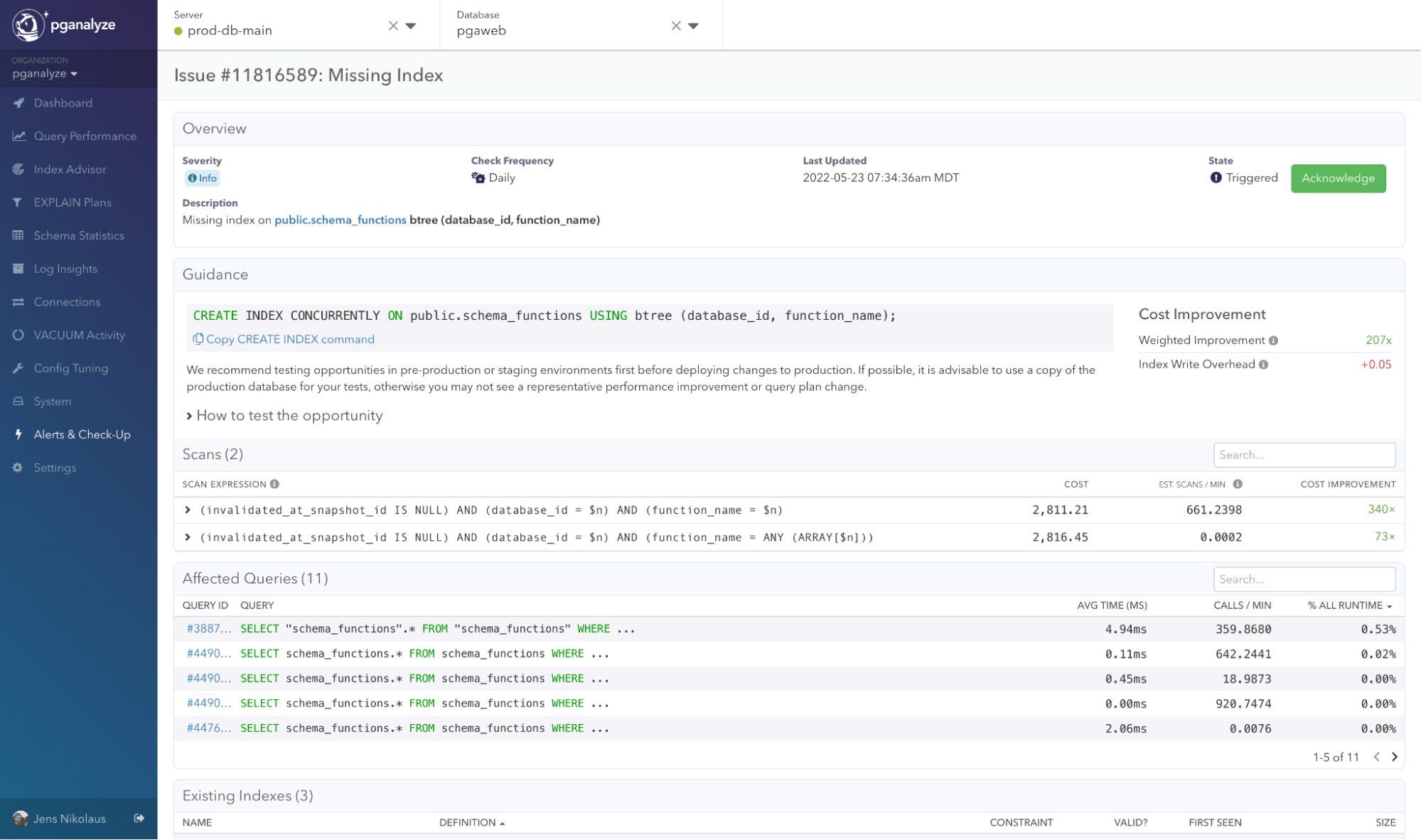
Missing index issue page on the pganalyze Index Advisor
Use the missing index issue page information to reason and test our recommendation. We share what scans and queries are affected by the opportunity, so you can benchmark against them in a copy of your production environment.
Different variants of indexes are tried during the Index Advisor recommendation process to see what produces the lowest cost (and thus the lowest estimated I/O). When the Index Advisor finds a recommendation, it will show an expected cost improvement.
The cost improvement is an average across the individual cost improvements for each scan that can benefit from the query, weighted by the frequency of the scan (based on the queries that contain the scan). More frequent queries will have a more significant impact on the overall weighted cost improvement.
By making the data accessible like this, we want to enable anybody on your development team to make a case for adding an index or not. As mentioned above, we aim to provide context and education to help you reason about a recommendation and give you enough confidence to act on it.
We want to enable anybody on your development team to make a case for adding an index or not.
As published in one of our previous blog posts, one of our core design principles is Telling a Story. You can check out this blog post to read about all of our Design Principles.
Set up alerts for Index Advisor
Index Advisor integrates with our Alerts & Check-up feature so that you can set up alert rules for new index opportunities. In addition, you can use our Slack integration to send alerts to the places where your team works. With the pganalyze Index Advisor, you can focus on developing your apps – we notify you when there are new opportunities for you.
What’s next for Index Advisor?
With this launch, our work on the pganalyze Index Advisor does not end, there are already multiple things in the pipeline, such as index consolidation recommendations, and resolving known limitations.
Conclusion
We are excited to see how this will help you develop indexing strategies and foster conversations with your teams. So give it a try now, and let us know what you think.
We would love to hear any ideas or feedback, either via email or join our next webinar on Postgres Indexing to get more information on how Postgres and the Index Advisor work.
P.S. We are hiring new engineering team members at pganalyze soon. Follow us on Twitter to find out more.
Share this article: Click here to share this article with your peers on twitter.
See a behind-the-scences on the Indexing Engine and Index Advisor in our webinar re-run

On June 16th, 2022, we hosted a webinar and walked through our approach for creating the best Postgres indexes, and our thinking behind the new pganalyze Indexing Engine.
You can watch the webinar here: Webinar Re-Run: How to reason about indexing your Postgres database.