


How Postgres Chooses Which Index To Use For A Query
 By Lukas Fittl
By Lukas Fittl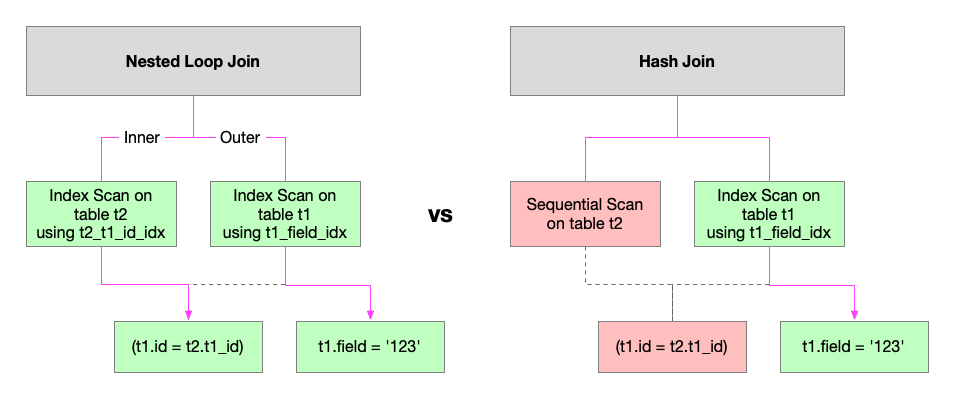
Using Postgres sometimes feels like magic. But sometimes the magic is too much, such as when you are trying to understand the reason behind a seemingly bad Postgres query plan.
I’ve often times found myself in a situation where I asked myself: “Postgres, what are you thinking?”. Staring at an EXPLAIN plan, seeing a Sequential Scan, and being puzzled as to why Postgres isn’t doing what I am expecting.
This has led me down the path of reading the Postgres source, in search for answers. Why is Postgres choosing a particular index over another one, or not choosing an index altogether?
In this blog post I aim to give an introduction to how the Postgres planner analyzes your query, and how it decides which indexes to use. Additionally, we’ll look at a puzzling situation where the join type can impact which indexes are being used.
We’ll look at a lot of Postgres source code, but if you are short on time, you might want to jump to how B-tree index costing works, and why Nested Loop Joins impact index usage.
We’ll also talk about an upcoming pganalyze feature at the very end!
A tour of Postgres: Parse analysis and early stages of planning
To start with, let’s look at a query’s lifecycle in Postgres. There are four important steps in how a query is handled:
- Parsing: Turning query text into an Abstract Syntax Tree (AST)
- Parse analysis: Turning table names into actual references to table objects
- Planning: Finding and creating the optimal query plan
- Execution: Executing the query plan
For understanding how the planner chooses which indexes to use, let’s first take a look at what parse analysis does.
Whilst there are multiple entry points into parse analysis, depending if you have query parameters or not, the core function in parse analysis is transformStmt (source):
/*
* transformStmt -
* recursively transform a Parse tree into a Query tree.
*/
Query *
transformStmt(ParseState *pstate, Node *parseTree)
{
This takes the raw parse tree output (from the first step), and returns a Query struct. It has a lot of specific cases, as it handles both regular SELECTs as well as UPDATEs and other DML statements. Note that utility statements (DDL, etc) mostly get passed through to the execution phase.
Since we are interested in tables and indexes, let’s take a closer look at how parse analysis handles the FROM clause:
void
transformFromClause(ParseState *pstate, List *frmList)
{
ListCell *fl;
/*
* The grammar will have produced a list of RangeVars, RangeSubselects,
* RangeFunctions, and/or JoinExprs. Transform each one (possibly adding
* entries to the rtable), check for duplicate refnames, and then add it
* to the joinlist and namespace.
*/
foreach(fl, frmList)
{
…
n = transformFromClauseItem(pstate, n,
&nsitem,
&namespace);
…
/*
* transformFromClauseItem -
* Transform a FROM-clause item, adding any required entries to the
* range table list being built in the ParseState, and return the
* transformed item ready to include in the joinlist. Also build a
* ParseNamespaceItem list describing the names exposed by this item.
* This routine can recurse to handle SQL92 JOIN expressions.
*/
static Node *
transformFromClauseItem(ParseState *pstate, Node *n,
ParseNamespaceItem **top_nsitem,
List **namespace)
{
…
Postgres already separates between the range table list (essentially a list of all the tables referenced by the query), and the joinlist. This distinction will also be visible at a later point in the planner.
Note that at this point Postgres has not yet made up its mind which indexes to use - it just decided that the FROM reference you called “foobar” is actually the table “foobar” in the “public” schema with OID 16424.
This information now gets stored in the Query struct, which is the result of the parse analysis phase. This Query struct is then passed into the planner, and that’s where it gets interesting.
Four levels of planning a query
Commonly we would start with the standard_planner (source) function as an entry point into the Postgres planner:
PlannedStmt *
standard_planner(Query *parse, const char *query_string, int cursorOptions,
ParamListInfo boundParams)
{
This takes our Query struct, and ultimately returns a PlannedStmt. For reference, the PlannedStmt struct (source) looks like this:
/* ----------------
* PlannedStmt node
*
* The output of the planner is a Plan tree headed by a PlannedStmt node.
* PlannedStmt holds the "one time" information needed by the executor.
* ----------------
*/
typedef struct PlannedStmt
{
NodeTag type;
CmdType commandType; /* select|insert|update|delete|utility */
…
struct Plan *planTree; /* tree of Plan nodes */
…
The tree of plan nodes is what you would be familiar with if you’ve looked at an EXPLAIN output before - ultimately EXPLAIN is based on walking that plan tree and showing you a text/JSON/etc version of it.
The core function of the planner is best described in these lines of standard_planner:
/* primary planning entry point (may recurse for subqueries) */
root = subquery_planner(glob, parse, NULL,
false, tuple_fraction);
/* Select best Path and turn it into a Plan */
final_rel = fetch_upper_rel(root, UPPERREL_FINAL, NULL);
best_path = get_cheapest_fractional_path(final_rel, tuple_fraction);
top_plan = create_plan(root, best_path);
The planner first creates what are called “paths” using the subquery_planner (which may recursively call itself), and then the planner picks the best path. Best on this best path, the actual plan tree is constructed.
For understanding how the planner chose which indexes to use, we must therefore look at paths, not at plan nodes. Let’s see what subquery_planner (source) does:
/*--------------------
* subquery_planner
* Invokes the planner on a subquery. We recurse to here for each
* sub-SELECT found in the query tree.
…
*/
PlannerInfo *
subquery_planner(PlannerGlobal *glob, Query *parse,
PlannerInfo *parent_root,
bool hasRecursion, double tuple_fraction)
{
As described in the comment, this handles each sub-SELECT separately - but note that even if the original query contains a written sub-SELECT, the planner may optimize it away to pull it up into the parent planning process, if possible.
For the purposes of focusing on index choice, here are the two key parts of subquery_planner:
/*
* Do the main planning. If we have an inherited target relation, that
* needs special processing, else go straight to grouping_planner.
*/
if (parse->resultRelation &&
rt_fetch(parse->resultRelation, parse->rtable)->inh)
inheritance_planner(root);
else
grouping_planner(root, false, tuple_fraction);
…
/*
* Make sure we've identified the cheapest Path for the final rel. (By
* doing this here not in grouping_planner, we include initPlan costs in
* the decision, though it's unlikely that will change anything.)
*/
set_cheapest(final_rel);
This method also optimizes for the cheapest path - we’ll see more on that in a moment. But for now, let’s go deeper down the rabbit hole and look at grouping_planner (source):
/* --------------------
* grouping_planner
* Perform planning steps related to grouping, aggregation, etc.
*
* This function adds all required top-level processing to the scan/join
* Path(s) produced by query_planner.
*
* --------------------
*/
static void
grouping_planner(PlannerInfo *root, bool inheritance_update,
double tuple_fraction)
{
Reading through its code, turns out we’re still not there. It’s actually query_planner that we are looking for, as described in this comment:
RelOptInfo *current_rel;
…
/*
* Generate the best unsorted and presorted paths for the scan/join
* portion of this Query, ie the processing represented by the
* FROM/WHERE clauses. (Note there may not be any presorted paths.)
* We also generate (in standard_qp_callback) pathkey representations
* of the query's sort clause, distinct clause, etc.
*/
current_rel = query_planner(root, standard_qp_callback, &qp_extra);
Before we dive into the query_planner method, let’s pause for a moment and look at what the result of query_planner is, the RelOptInfo struct:
Breaking down a query into tables being scanned (RelOptInfo and RestrictInfo structs)
In the Postgres planner, RelOptInfo is best described as the internal representation of a particular table that is being scanned (with either a sequential scan, or an index scan).
When trying to understand how Postgres interprets your query, adding debug information that shows RelOptInfo would be the closest that you can get to seeing which tables Postgres is going to scan, and how it makes a decision between different scan methods, such as an Index Scan.
RelOptInfo (source) has many details to it, but the key parts for our focus on indexing are these:
/*----------
* RelOptInfo
* Per-relation information for planning/optimization
…
* pathlist - List of Path nodes, one for each potentially useful
* method of generating the relation
…
* baserestrictinfo - List of RestrictInfo nodes, containing info about
* each non-join qualification clause in which this relation
* participates (only used for base rels)
…
* joininfo - List of RestrictInfo nodes, containing info about each
* join clause in which this relation participates
…
*/
typedef struct RelOptInfo
{
…
List *pathlist; /* Path structures */
…
List *baserestrictinfo; /* RestrictInfo structures (if base rel) */
…
List *joininfo; /* RestrictInfo structures for join clauses
* involving this rel */
…
}
Before we interpret this, let’s look at RestrictInfo (source):
/*
* Restriction clause info.
*
* We create one of these for each AND sub-clause of a restriction condition
* (WHERE or JOIN/ON clause). Since the restriction clauses are logically
* ANDed, we can use any one of them or any subset of them to filter out
* tuples, without having to evaluate the rest.
..
*/
typedef struct RestrictInfo
{
NodeTag type;
Expr *clause; /* the represented clause of WHERE or JOIN */
…
}
A note on terminology: This references “base relations”, which are relations (aka tables) that are looked at solely on their individual basis, as compared to in the context of a JOIN.
In the code sample, RestrictInfo is how our WHERE clause and JOIN conditions get represented. This is the part that is key to understanding how Postgres compares your query against the indexes that exist.
You can think about it this way - for each table that’s included in the query, Postgres generates two lists of “restriction” clauses:
- Base restriction clauses: Typically part of your WHERE clause, and are expressions that involve only the table itself - for example
users.id = 123 - Join clauses: Typically part of your JOIN clause, and expressions that involve multiple tables - for example
users.id = comments.user_id
Note the reason that Postgres calls these “restriction” clauses is because they restrict (or filter) the amount of data that is being returned from your table. And how can we effectively filter data from a table? By using an index!
The base restriction clauses will typically be used to filter down the amount of data that is being returned from the table. But join clauses oftentimes will not, as they are only used as part of the matching of rows that happens during the JOIN operation.
The one exception to this are Nested Loop Joins - but we’ll come back to that.

Choosing different paths and scan methods
Let’s go back to query_planner (source), and what it does:
/*
* query_planner
* Generate a path (that is, a simplified plan) for a basic query,
* which may involve joins but not any fancier features.
*
* Since query_planner does not handle the toplevel processing (grouping,
* sorting, etc) it cannot select the best path by itself. Instead, it
* returns the RelOptInfo for the top level of joining, and the caller
* (grouping_planner) can choose among the surviving paths for the rel.
…
*/
RelOptInfo *
query_planner(PlannerInfo *root,
query_pathkeys_callback qp_callback, void *qp_extra)
{
…
/*
* Construct RelOptInfo nodes for all base relations used in the query.
*/
add_base_rels_to_query(root, (Node *) parse->jointree);
…
/*
* Ready to do the primary planning.
*/
final_rel = make_one_rel(root, joinlist);
return final_rel;
}
The main point of query_planner itself is to create a set of RelOptInfo nodes, do a bunch of processing involving them, and then passing them to make_one_rel. As that name says, it creates one “final rel”, which is also a RelOptInfo node, that is then used to create our final plan.
We’ve looked at a bunch of code already, but now it’s time to get to the exciting part!
The implementation of make_one_rel (source) sits in a file with the important sounding name of allpaths.c - and as referenced earlier, when we talk about plan choices, we need to understand which path is chosen, as that is used to then create a plan node.
/*
* make_one_rel
* Finds all possible access paths for executing a query, returning a
* single rel that represents the join of all base rels in the query.
*/
RelOptInfo *
make_one_rel(PlannerInfo *root, List *joinlist)
{
…
/*
* Compute size estimates and consider_parallel flags for each base rel.
*/
set_base_rel_sizes(root);
…
/*
* Generate access paths for each base rel.
*/
set_base_rel_pathlists(root);
/*
* Generate access paths for the entire join tree.
*/
rel = make_rel_from_joinlist(root, joinlist);
return rel;
}
Paths are chosen in three steps:
- Estimate the sizes of the involved tables
- Find the best path for each base relation
- Find the best path for the entire join tree
The first step is mainly concerned with size estimates as they relate to the output of scanning the relation. This impacts the cost and rows numbers you are familiar with from EXPLAIN - and this may impact joins, but typically should not directly impact index usage.
Now step 2 is key to our goal here. And set_base_rel_pathlists ultimately calls set_plain_rel_pathlist (source), which finally looks like what we are interested in:
/*
* set_plain_rel_pathlist
* Build access paths for a plain relation (no subquery, no inheritance)
*/
static void
set_plain_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, RangeTblEntry *rte)
{
…
/* Consider sequential scan */
add_path(rel, create_seqscan_path(root, rel, required_outer, 0));
/* If appropriate, consider parallel sequential scan */
if (rel->consider_parallel && required_outer == NULL)
create_plain_partial_paths(root, rel);
/* Consider index scans */
create_index_paths(root, rel);
/* Consider TID scans */
create_tidscan_paths(root, rel);
}
Where Index Scans are made
Creating the two types of index scans: plain vs parameterized
Let’s look at create_index_paths (source), since we want to see how indexes are picked:
/*
* create_index_paths()
* Generate all interesting index paths for the given relation.
* Candidate paths are added to the rel's pathlist (using add_path).
*
* To be considered for an index scan, an index must match one or more
* restriction clauses or join clauses from the query's qual condition,
* or match the query's ORDER BY condition, or have a predicate that
* matches the query's qual condition.
*
* There are two basic kinds of index scans. A "plain" index scan uses
* only restriction clauses (possibly none at all) in its indexqual,
* so it can be applied in any context. A "parameterized" index scan uses
* join clauses (plus restriction clauses, if available) in its indexqual.
* When joining such a scan to one of the relations supplying the other
* variables used in its indexqual, the parameterized scan must appear as
* the inner relation of a nestloop join; it can't be used on the outer side,
* nor in a merge or hash join.
…
*/
void
create_index_paths(PlannerInfo *root, RelOptInfo *rel)
{
…
/* Examine each index in turn */
foreach(lc, rel->indexlist)
{
IndexOptInfo *index = (IndexOptInfo *) lfirst(lc);
…
/*
* Ignore partial indexes that do not match the query.
*/
if (index->indpred != NIL && !index->predOK)
continue;
/*
* Identify the restriction clauses that can match the index.
*/
match_restriction_clauses_to_index(root, index, &rclauseset);
/*
* Build index paths from the restriction clauses. These will be
* non-parameterized paths. Plain paths go directly to add_path(),
* bitmap paths are added to bitindexpaths to be handled below.
*/
get_index_paths(root, rel, index, &rclauseset,
&bitindexpaths);
/*
* Identify the join clauses that can match the index. For the moment
* we keep them separate from the restriction clauses.
*/
match_join_clauses_to_index(root, rel, index,
&jclauseset, &joinorclauses);
…
/*
* If we found any plain or eclass join clauses, build parameterized
* index paths using them.
*/
if (jclauseset.nonempty || eclauseset.nonempty)
consider_index_join_clauses(root, rel, index,
&rclauseset,
&jclauseset,
&eclauseset,
&bitjoinpaths);
}
…
}
There are a lot of things to take in here - and we’ve already removed BitmapOr/BitmapAnd index scans from this code sample.
First of all, this builds two types of index scans:
- Plain index scans, that only use the base restriction clauses
- Parameterized index scans, that use both base restriction clauses and join clauses
We’ll talk more about the second case in a moment.
Other key aspects to understand:
- Partial indexes (i.e. those with an attached WHERE clause on the index definition) are matched against the set of restriction clauses and discarded here if they don’t match
- Each index is both considered for an Index Scan and Index Only Scan (through the “build_index_paths” method), as well as for a Bitmap Heap Scan / Bitmap Index Scan
- Each potential way of using an index gets a cost assigned - and this cost decides whether Postgres actually chooses the index (see earlier notion of the “best path”), or not
For understanding how costing works, you can look at the cost_index function (source), which gets called from build_index_paths through a few hoops.
/*
* cost_index
* Determines and returns the cost of scanning a relation using an index.
…
* In addition to rows, startup_cost and total_cost, cost_index() sets the
* path's indextotalcost and indexselectivity fields. These values will be
* needed if the IndexPath is used in a BitmapIndexScan.
*/
void
cost_index(IndexPath *path, PlannerInfo *root, double loop_count,
bool partial_path)
{
…
/*
* Call index-access-method-specific code to estimate the processing cost
* for scanning the index, as well as the selectivity of the index (ie,
* the fraction of main-table tuples we will have to retrieve) and its
* correlation to the main-table tuple order.
*/
amcostestimate(root, path, loop_count,
&indexStartupCost, &indexTotalCost,
&indexSelectivity, &indexCorrelation,
&index_pages);
Whilst there are other factors in costing an index scan, the main responsibility falls to the Index Access Method.
Understanding B-tree index cost estimates
The most common index access method (or index type) is B-tree, so let’s look at btcostestimate:
void
btcostestimate(PlannerInfo *root, IndexPath *path, double loop_count,
Cost *indexStartupCost, Cost *indexTotalCost,
Selectivity *indexSelectivity, double *indexCorrelation,
double *indexPages)
{
…
/*
* For a btree scan, only leading '=' quals plus inequality quals for the
* immediately next attribute contribute to index selectivity (these are
* the "boundary quals" that determine the starting and stopping points of
* the index scan).
*/
indexBoundQuals = …
/*
* If the index is partial, AND the index predicate with the
* index-bound quals to produce a more accurate idea of the number of
* rows covered by the bound conditions.
*/
selectivityQuals = add_predicate_to_index_quals(index, indexBoundQuals);
btreeSelectivity = clauselist_selectivity(root, selectivityQuals,
index->rel->relid,
JOIN_INNER,
NULL);
numIndexTuples = btreeSelectivity * index->rel->tuples;
…
costs.numIndexTuples = numIndexTuples;
genericcostestimate(root, path, loop_count, &costs);
…
As you can see a lot revolves around determining how many index tuples will be matched by the scan - as that’s the main expensive portion of querying a B-tree index.
The first step is determining the boundaries of the index scan, as it relates to the data stored in the index. In particular this is relevant for multi-column B-tree indexes, where only a subset of the columns might match the query.
You may have heard before about the best practice of ordering B-tree columns so the columns that are queried by an equality comparison (= operator) are put first, followed by one optional inequality comparison (<> operator), followed by any other columns. This recommendation is based on the physical structure of the B-tree index, and the cost model also reflects this constraint.
Put differently: The more specific you are with matching equality comparisons, the less parts of the index have to be scanned. This is represented here by the calculation of “btreeSelectivity”. If this number is small, the cost of the index scan will be less, as determined by “genericcostestimate” based on the estimated number of index tuples being scanned.
For creating the ideal B-tree index, you would:
- Focus on indexing columns used in equality comparisons
- Index the columns with the best selectivity (i.e. being most specific), so that only a small portion of the index has to be scanned
- Involve a small number of columns (possibly only one), to keep the index size small - and thus reduce the total number of pages in the index
If you follow these steps, you will create a B-tree index that has a low cost, and that Postgres should choose.
Now, there is one more thing we wanted to talk about, and that involves the notion of Parameterized Index Scans:
Parameterized Index Scans, or: Why Nested Loop are sometimes a good join type
As noted earlier, when Postgres looks at the potential index scans, it creates both plain index scans, and parameterized index scans.
Plain index scans only involve parts of your query that involve the table itself, and would typically reference the clauses found in the WHERE clause.
Parameterized index scans on the other hand involve the part of your query that references two different tables. Oftentimes you would find these clauses in the JOIN clause.
Let’s take a look at a practical example. Assume the following schema and indexes:
CREATE TABLE t1 (
id bigint PRIMARY KEY,
field text
);
CREATE TABLE t2 (
id bigint PRIMARY KEY,
t1_id bigint,
other_field text
);
CREATE INDEX t1_field_idx ON t1(field);
CREATE INDEX t2_t1_id_idx ON t2(t1_id);
And this query:
SELECT *
FROM t1
JOIN t2 ON (t1.id = t2.t1_id)
WHERE t1.field = '123'
We have two tables to scan - t1 and t2.
For t1, we can utilize a plain index scan on the t1_field_idx index - and that will perform well, since we have a specific value that is present in the query, that ideally matches a small amount of rows.
When we run an EXPLAIN on the query, the simplest plan will look like this:
EXPLAIN SELECT *
FROM t1
JOIN t2 ON (t1.id = t2.t1_id)
WHERE t1.field = '123';
QUERY PLAN
---------------------------------------------------------------------------------------
Hash Join (cost=13.74..37.26 rows=5 width=88)
Hash Cond: (t2.t1_id = t1.id)
-> Seq Scan on t2 (cost=0.00..20.70 rows=1070 width=48)
-> Hash (cost=13.67..13.67 rows=6 width=40)
-> Bitmap Heap Scan on t1 (cost=4.20..13.67 rows=6 width=40)
Recheck Cond: (field = '123'::text)
-> Bitmap Index Scan on t1_field_idx (cost=0.00..4.20 rows=6 width=0)
Index Cond: (field = '123'::text)
(8 rows)
Or put visually:
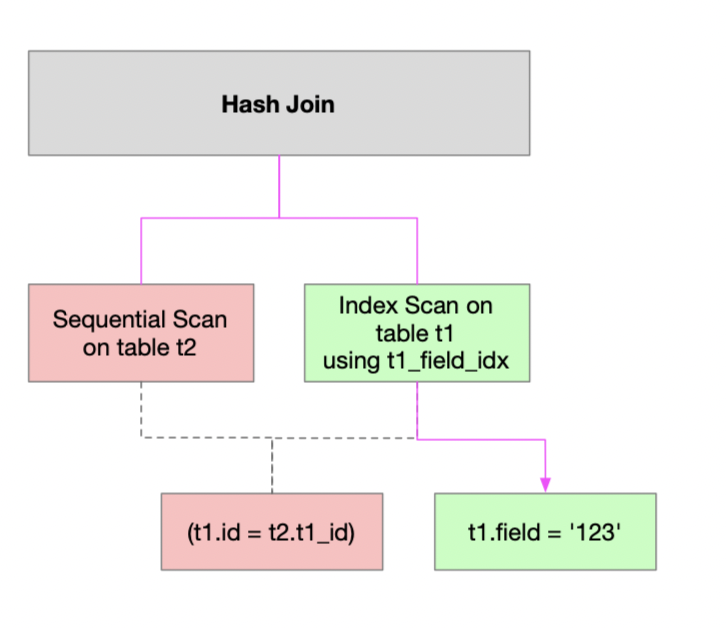
As we can see Postgres uses a Sequential Scan on t2. Let’s add some more data into the tables, to see if that changes the plan:
INSERT INTO t1 SELECT val, val::text FROM generate_series(0, 1000) AS x(val);
INSERT INTO t2 SELECT val, val, val::text FROM generate_series(0, 1000) AS x(val);
Note that we are effectively creating exactly one entry that matches the t1.field = '123' condition, and we are also creating exactly one t2 entry for each t1 entry.
If we re-run the EXPLAIN, we get the following plan:
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.55..16.60 rows=1 width=30)
-> Index Scan using t1_field_idx on t1 (cost=0.28..8.29 rows=1 width=11)
Index Cond: (field = '123'::text)
-> Index Scan using t2_t1_id_idx on t2 (cost=0.28..8.29 rows=1 width=19)
Index Cond: (t1_id = t1.id)
(5 rows)
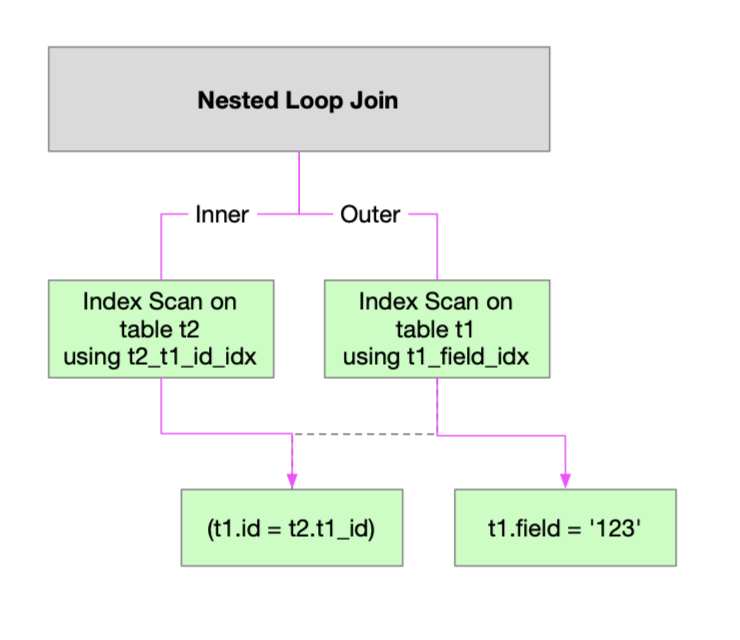
As you can see, we now get an index scan on t2_t1_id_idx. This shows a Parameterized Index Scan in action - this is only possible because the join chosen by Postgres is a Nested Loop - not a Hash Join or Merge Join.
A quick summary of how different join types impact index usage:
- Merge Join: Needs sorted output from the scan node (thus can benefit from a sorted index like B-tree), but doesn’t use the JOIN clause to restrict the data when scanning the table
- Hash Join: Doesn’t need sorted output, and doesn’t use the JOIN clause to restrict the data when scanning the table
- Nested Loop Join: Doesn’t need sorted output from the scan node, but for one of the two tables uses the JOIN clause to restrict the data when scanning the table
Understanding what’s in your WHERE, your JOIN clause and your likely JOIN type is key, as all three will impact index usage.
If you see a surprising Sequential Scan, you might want to review whether all possible index scans were parameterized index scans, and how the plan changes when you add an additional WHERE clause.
New features coming soon to pganalyze
If you find you’re having a hard time reasoning about all of this, you are not alone!
The reason we’ve spent a lot of time looking through these parts of the Postgres source code, is because they form the basis of a new upcoming version of the Index Advisor.
And as part of the new Index Advisor, we’ll show you additional information for all scans on a table, to help you assess how Postgres uses existing indexes, and what the best indexing strategy might be.
Here is a sneak peek from our current design iteration:
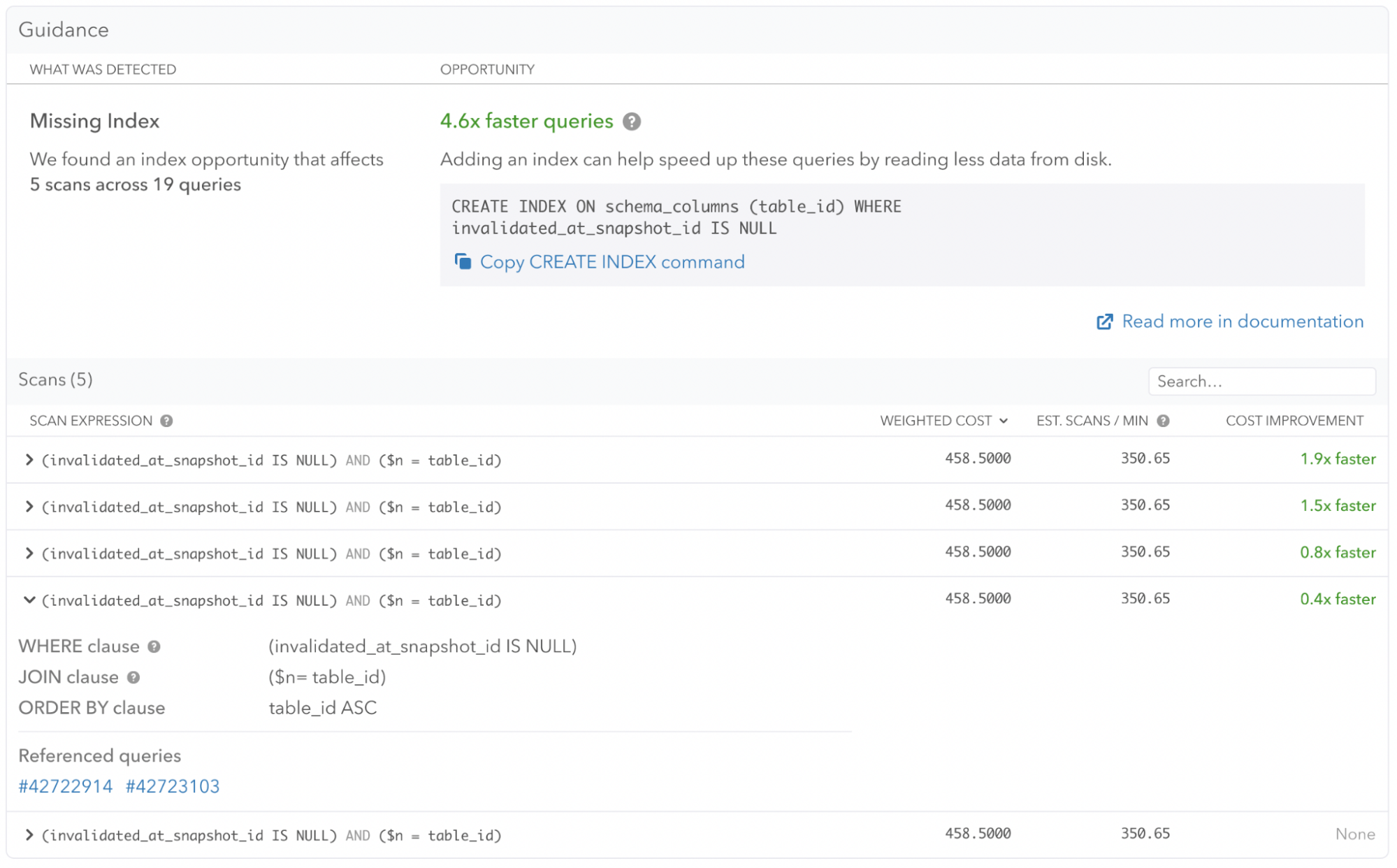
The same WHERE clause and JOIN clause data from the Postgres planner is shown in the Scans list, to help you make an assessment of how Postgres builds Plain Index Scans and Parameterized Index Scans for your queries.
But more on this another day!
Conclusion
In this post we’ve gone down and chased through the Postgres source code until we’ve found the place where indexing decisions happen. We’ve looked at B-tree costing in particular, and looked at a puzzling case of how Nested Loops can affect index usage, by allowing the use of Parameterized Index Scans.
If you optimize your queries, it helps to understand which tables you are scanning, and what the involved WHERE and JOIN clauses are. Additionally, it’s important to understand the different join types, and that only Nested Loop joins can make use of indexes on columns in the JOIN clause.
Do you think your peers might be interested in this article? Share this on Twitter.
Other helpful resources
-
Using Postgres CREATE INDEX: Understanding operator classes, index types & more
-
How we deconstructed the Postgres planner to find indexing opportunities
-
A better way to index your Postgres database: pganalyze Index Advisor
-
Best Practices for Optimizing Postgres Query Performance eBook
-
5mins of Postgres E6: Optimizing Postgres Text Search with Trigrams and GiST indexes