


Understanding Postgres GIN Indexes: The Good and the Bad
 By Lukas Fittl
By Lukas Fittl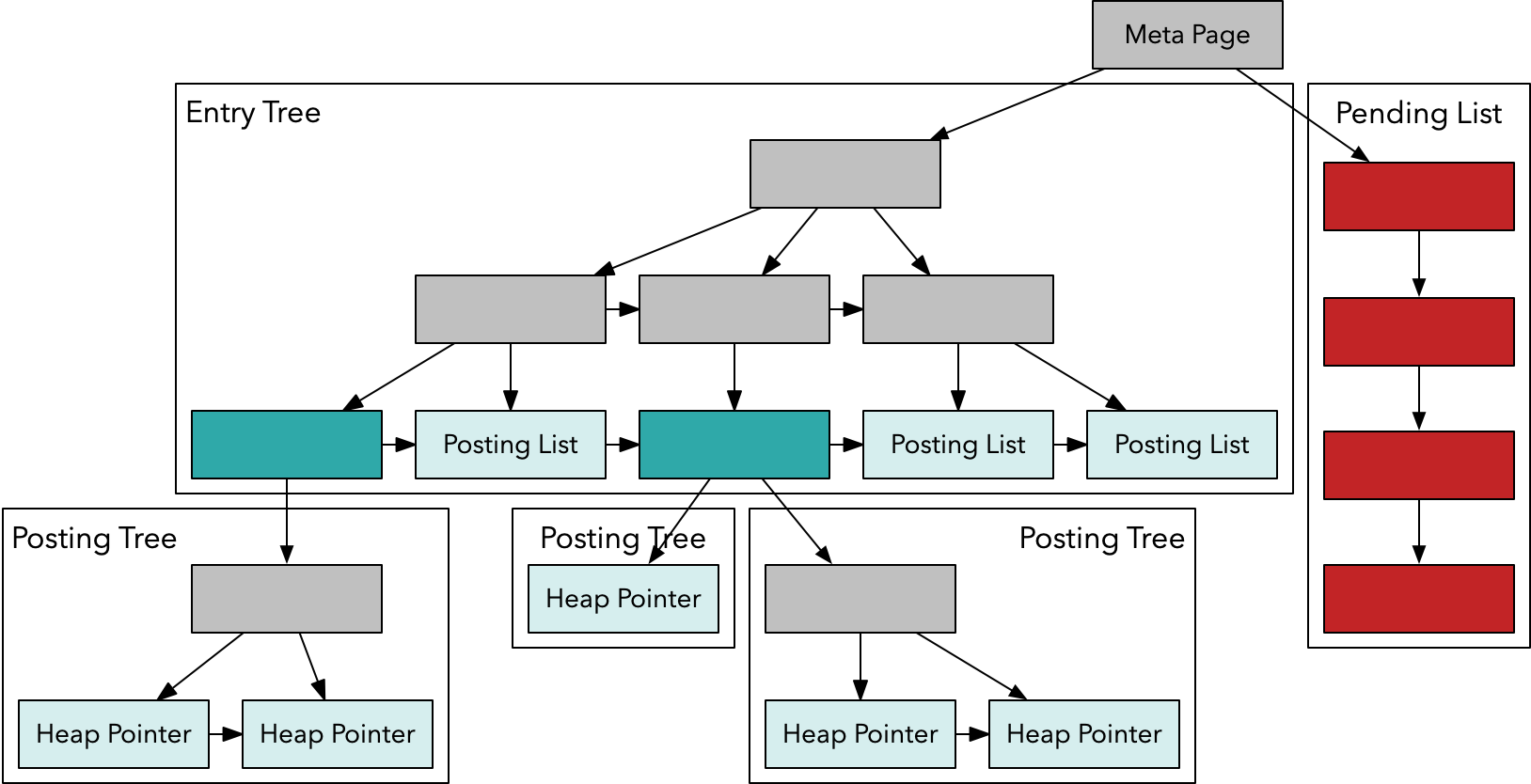
Adding, tuning and removing indexes is an essential part of maintaining an application that uses a database. Oftentimes, our applications rely on sophisticated database features and data types, such as JSONB, array types or full text search in Postgres. A simple B-tree index does not work in such situations, for example to index a JSONB column. Instead, we need to look beyond, to GIN indexes.
Almost 15 years ago to the dot, GIN indexes were added in Postgres 8.2, and they have since become an essential tool in the application DBA’s toolbox. GIN indexes can seem like magic, as they can index what a normal B-tree cannot, such as JSONB data types and full text search. With this great power comes great responsibility, as GIN indexes can have adverse effects if used carelessly.
In this article, we’ll take an in-depth look at GIN indexes in Postgres, building on, and referencing many great articles that have been written over the years by the community. We’ll start by reviewing what GIN indexes can do, how they are structured, and their most common use cases, such as for indexing JSONB columns, or to support Postgres full text search.
But, understanding the fundamentals is only part of the puzzle. It’s much better when we can also learn from real world examples on busy databases. We’ll review a specific situation that the GitLab database team found themselves in this year, as it relates to write overhead caused by GIN indexes on a busy table with more than 1000 updates per minute.
And we’ll conclude with a review of the trade-offs between the GIN write overhead and the possible performance gains. Plus: We’ve added support for GIN index recommendations to the pganalyze Index Advisor.
To start with, let’s review what a GIN index looks like:
GIN Index in Postgres: What is it actually?
“The GIN index type was designed to deal with data types that are subdividable and you want to search for individual component values (array elements, lexemes in a text document, etc)” - Tom Lane
The GIN index type was initially created by Teodor Sigaev and Oleg Bartunov, first released in Postgres 8.2, on December 5, 2006 - almost 15 years ago. Since then, GIN has seen many improvements, but the fundamental structure remains similar. GIN stands for “Generalized Inverted iNdex”. “Inverted” refers to the way that the index structure is set up, building a table-encompassing tree of all column values, where a single row can be represented in many places within the tree. By comparison, a B-tree index generally has one location where an index entry points to a specific row.
Another way of explaining GIN indexes comes from a presentation by Oleg Bartunov and Alexander Korotkov at PGConf.EU 2012 in Prague. They describe a GIN index like the table of contents in a book, where the heap pointers (to the actual table) are the page numbers. Multiple entries can be combined to yield a specific result, like the search for “compensation accelerometers” in this example:
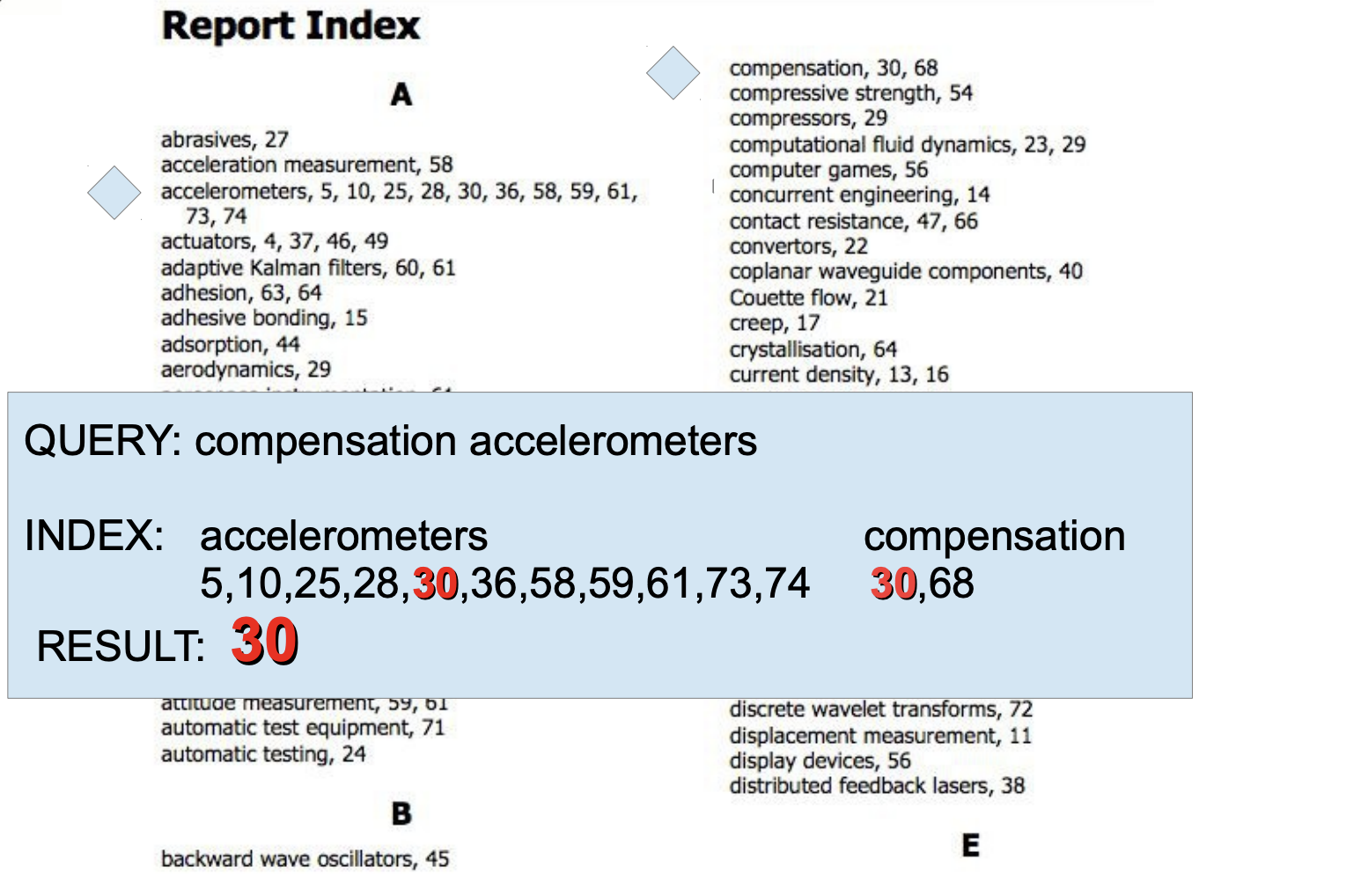
It’s important to note that the exact mapping of a column of a given data type is dependent on the GIN index operator class. That means, instead of having a uniform representation of data in the index, like with B-trees, a GIN index can have very different index contents depending on which data type and operator class you are using. Some data types, such as JSONB have more than one GIN operator class to support the most optimal index structure for specific query patterns.
Before we move on, one more thing to know: GIN indexes only support Bitmap Index Scans (not Index Scan or Index Only Scan), due to the fact that they only store parts of the row values in each index page. Don’t be surprised when EXPLAIN always shows Bitmap Index / Heap Scans for your GIN indexes.
Let’s take a look at a few examples:
Indexing tsvector columns for Postgres full text search
The initial motivation for GIN indexes was full text search. Before GIN was added, there was no way to index full text search in Postgres, instead requiring a very slow sequential scan of the table.
We’ve previously written about Postgres full text search with Django, as well as how to do it with Ruby on Rails on the pganalyze blog.
A simple example for a full text search index looks like this:
CREATE INDEX pgweb_idx ON pgweb USING GIN (to_tsvector('english', body));
This uses an expression index to create a GIN index that contains the indexed tsvector values for each row. You can then query like this:
SELECT title
FROM pgweb
WHERE to_tsvector('english', body) @@ to_tsquery('english', 'friend');
As described in the Postgres documentation, the tsvector GIN index structure is focused on lexemes:
“GIN indexes are the preferred text search index type. As inverted indexes, they contain an index entry for each word (lexeme), with a compressed list of matching locations. Multi-word searches can find the first match, then use the index to remove rows that are lacking additional words.”
GIN indexes are the best starting point when using Postgres Full Text Search. There are situations where a GIST index might be preferred (see the Postgres documentation for details), and if you run your own server you could also consider the newer RUM index types available through an extension.
Let’s see what else GIN has to offer:
Indexing LIKE searches with Trigrams and gin_trgm_ops
Sometimes Full Text Search isn’t the right fit, but you find yourself needing to index a LIKE search on a particular column:
CREATE TABLE test_trgm (t text);
SELECT * FROM test_trgm WHERE t LIKE '%foo%bar';
Due to the nature of the LIKE operation, which supports arbitrary wildcard expressions, this is fundamentally hard to index. However, the pg_trgm extension can help. When you create an index like this:
CREATE INDEX trgm_idx ON test_trgm USING gin (t gin_trgm_ops);
Postgres will split the row values into trigrams, allowing indexed searches:
EXPLAIN SELECT * FROM test_trgm WHERE t LIKE '%foo%bar';
QUERY PLAN
------------------------------------------------------------------------
Bitmap Heap Scan on test_trgm (cost=16.00..20.02 rows=1 width=32)
Recheck Cond: (t ~~ '%foo%bar'::text)
-> Bitmap Index Scan on trgm_idx (cost=0.00..16.00 rows=1 width=0)
Index Cond: (t ~~ '%foo%bar'::text)
(4 rows)
Effectiveness of this method varies with the exact data set. But when it works, it can speed up searches on arbitrary text data quite significantly.

PostgreSQL, JSONB and GIN Indexes
JSONB was added to Postgres almost 10 years after GIN indexes were introduced - and it shows the flexibility of the GIN index type that they are the preferred way to index JSONB columns.
Postgres GIN index for JSONB columns using jsonb_ops and jsonb_path_ops
With JSONB in Postgres we gain the flexibility of not having to define our schema upfront, but instead we can dynamically add data to a column in our table in JSON format.
The most basic GIN index example for JSONB looks like this:
CREATE TABLE test (
id bigserial PRIMARY KEY,
data jsonb
);
INSERT INTO test(data) VALUES ('{"field": "value1"}');
INSERT INTO test(data) VALUES ('{"field": "value2"}');
INSERT INTO test(data) VALUES ('{"other_field": "value42"}');
CREATE INDEX ON test USING gin(data);
As you can see with EXPLAIN, this is able to use the index, for example when querying for all rows that have the field key defined:
EXPLAIN SELECT * FROM test WHERE data ? 'field';
QUERY PLAN
----------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=8.00..12.01 rows=1 width=40)
Recheck Cond: (data ? 'field'::text)
-> Bitmap Index Scan on test_data_idx (cost=0.00..8.00 rows=1 width=0)
Index Cond: (data ? 'field'::text)
(4 rows)
The way this gets stored is based on the keys and values of the JSONB data. In the above test data, the default jsonb_ops operator class would store the following values in the GIN index, as separate entries: field, other_field, value1, value2, value42. Depending on the search the GIN index will combine multiple index entries to satisfy the specific query conditions.
Now, we can also use the non-default jsonb_path_ops operator class with a JSONB GIN index. This uses an optimized GIN index structure that would instead store the above data as three individual entries using a hash function: hashfn(field, value1), hashfn(field, value2) and hashfn(other_field, value42).
The jsonb_path_ops class is intended to efficiently support containment queries. First we specify the operator class during index creation:
CREATE INDEX ON test USING gin(data jsonb_path_ops);
And then we can use it for queries such as the following:
EXPLAIN SELECT * FROM test WHERE data @> '{"field": "value1"}';
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=8.00..12.01 rows=1 width=40)
Recheck Cond: (data @> '{"field": "value1"}'::jsonb)
-> Bitmap Index Scan on test_data_idx1 (cost=0.00..8.00 rows=1 width=0)
Index Cond: (data @> '{"field": "value1"}'::jsonb)
(4 rows)
As you can see it’s easy to index a JSONB column. Note that you could technically also index JSONB with other index types by taking specific parts of the data. For example, we could use a B-tree expression index to index the field keys:
CREATE INDEX ON test USING btree ((data ->> 'field'));
The Postgres query planner will then use the specific expression index behind the scenes, if your query matches the expression:
EXPLAIN SELECT * FROM test WHERE data->>'field' = 'value1';
QUERY PLAN
---------------------------------------------------------------------------
Index Scan using test_expr_idx on test (cost=0.13..8.15 rows=1 width=40)
Index Cond: ((data ->> 'field'::text) = 'value1'::text)
(2 rows)
There is one more thing we should look at with finding the right GIN index, and that is multi-column GIN indexes.
Multi-Column GIN Indexes, and Combining GIN and B-tree indexes
Often times you’ll have queries that filter on a column that uses a data type that’s ideal for GIN indexes, such as JSONB, but you are also filtering on another column, that is more of a typical B-tree index candidate:
CREATE TABLE records (
id bigserial PRIMARY KEY,
customer_id int4,
data jsonb
);
SELECT * FROM records WHERE customer_id = 123 AND data @> '{ "location": "New York" }';
In addition you might have a query like the following:
SELECT * FROM records WHERE customer_id = 123;
And you are considering which index to create for the two queries combined.
There are two fundamental strategies you can take:
- (1) Create two separate indexes, one on
customer_idusing a B-tree, and one ondatausing GIN- In this situation, for the first query, Postgres might use BitmapAnd to combine the index search results from both indexes to find the affected rows
- Whilst the idea of using two separate indexes sounds great in theory, in practice it often turns out to be the worse performing option. You can find some discussions about this on the Postgres mailing lists.
- (2) Create one multi-column GIN index on both
customer_idanddata- Note that multi-column GIN indexes don’t help much with making the index more effective, but they can help cover multiple queries with the same index
For implementing the second strategy, we need the help of the “btree_gin” extension in Postgres (part of contrib) that contains operator classes for data types that are not subdividable.
You can create the extension and the multi-column index like this:
CREATE EXTENSION btree_gin;
CREATE INDEX ON records USING gin (data, customer_id);
Note that index column order does not matter for GIN indexes. And as we can see, this gets used during query planning:
EXPLAIN SELECT * FROM records WHERE customer_id = 123 AND data @> '{ "location": "New York" }';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on records (cost=16.01..20.03 rows=1 width=41)
Recheck Cond: ((customer_id = 123) AND (data @> '{"location": "New York"}'::jsonb))
-> Bitmap Index Scan on records_customer_id_data_idx (cost=0.00..16.01 rows=1 width=0)
Index Cond: ((customer_id = 123) AND (data @> '{"location": "New York"}'::jsonb))
(5 rows)
It’s rather uncommon to use multi-column GIN indexes, but depending on your workload it might make sense. Remember that larger indexes mean more I/O, making index lookups slower, and writes more expensive.
The downside of GIN Indexes: Expensive Updates
As you saw in the examples above, GIN indexes are special because they often contain multiple index entries per single row that is being inserted. This is essential to enable the use cases that GIN supports, but causes one significant problem: Updating the index is expensive.
Due to the fact that a single row can cause 10s or worst case 100s of index entries to be updated, it’s important to understand the special fastupdate mechanism of GIN indexes.
By default fastupdate is enabled for GIN indexes, and it causes index updates to be deferred, so they can occur at a point where multiple updates have to be made, reducing the overhead for a single UPDATE, at the expense of having to do the work at a later point.
The data that is deferred is kept in the special pending list, which then gets flushed to the main index structure in one of three situations:
- The
gin_pending_list_limit(default of 4MB) is reached during a regular index update - Explicit call to the
gin_clean_pending_listfunction - Autovacuum on the table with the GIN index (GIN pending list cleanup happens at the end of vacuum)
As you can imagine this can be quite an expensive operation, which is why one symptom of index write overhead with GIN can be that every Nth INSERT or UPDATE statement suddenly is a lot slower, in case you run into the first scenario above, where the gin_pending_list_limit is reached.
This exact situation happened to the team at GitLab recently. Let’s look at a real life example of where GIN updates became a problem.
GIN trigram indexes: A lesson from GitLab
The team at GitLab often publishes their discussions of database optimizations publicly, and we can learn a lot from these interactions. A recent example discussed a GIN trigram index that caused merge requests to be quite slow occasionally:
“We can see there are a number of slow updates for updating a merge request. The interesting thing here is that we see very little locking statements (locking is logged after 5 seconds waiting), which suggests something else is occurring to make these slow.”
This was determined to be caused by the GIN pending list:
“Anecdotally, cleaning the gin index pending-list for the description field on the merge_requests table can cost multiple seconds. The overhead does increase when there are more pending entries to write to the index. In this informal survey of manually running gin_clean_pending_list( ‘index_merge_requests_on_description_trigram’::regclass ) the duration varied between 465 ms and 3155 ms.”
The team further investigated, and determined that the GIN pending list was flushed a very high number of times during business hours:
“this gin index’s pending list fills up roughly once every 2.7 seconds during the peak hours of a normal weekday.”
If you want to read the full story, GitLab’s Matt Smiley has done an excellent analysis of the problem they’ve encountered.
As we can see, getting good data about the actual overhead of GIN pending list updates is critical.

Measuring GIN pending list overhead and size
To validate whether the GIN pending list is a problem on a busy table, we can do a few things:
First, we could utilize the pgstatginindex function together with something like psql’s \watch command to keep a close eye on a particular index:
CREATE EXTENSION pgstattuple;
SELECT * FROM pgstatginindex('myindex');
version | pending_pages | pending_tuples
---------+---------------+----------------
2 | 0 | 0
(1 row)
Second, If you run your own database server, you can use “perf” dynamic tracepoints to measure calls to the ginInsertCleanup function in Postgres:
sudo perf probe -x /usr/lib/postgresql/14/bin/postgres ginInsertCleanup
sudo perf stat -a -e probe_postgres:ginInsertCleanup -- sleep 60
An alternate method, using DTrace, was described in a 2019 PGCon talk. The authors of that talk also ended up visualizing different gin_pending_list_limit and work_mem settings:
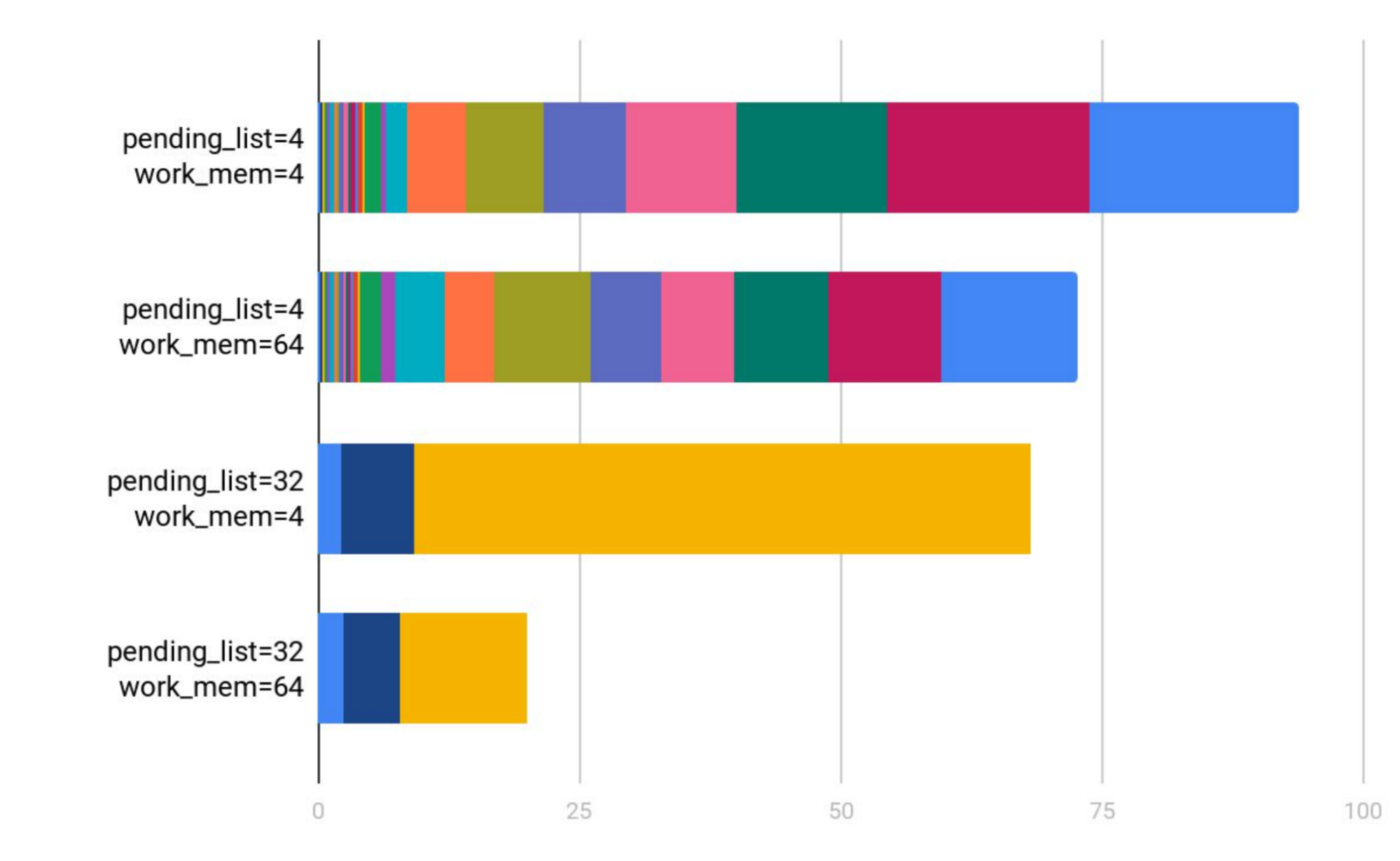
As they discovered, the memory limit during flushing of the pending list makes a quite noticable difference.
If you don’t have the luxury of direct access to your database server, you can estimate how often the pending list fills up based on the average size of index tuples and other statistics.
Now, if we determine that we have a problem, what can we do about it?
Strategies for dealing with GIN pending list update issues
There are multiple alternate ways you can resolve issues like the one GitLab encountered:
- (1) Reduce
gin_pending_list_limit- Have more frequent, smaller flushes
- This may sound odd - but
gin_pending_list_limitstarted out as being determined by work_mem (instead of being its own setting), and is only configurable separately since Postgres 9.5 - explaining the 4MB default, which may be too high in some cases
- (2) Increase
gin_pending_list_limit- Have more opportunities to cleanup the list outside of the regular workload
- (3) Turning off
fastupdate- Taking the overhead with each individual INSERT/UPDATE
- (4) Tune autovacuum to run more often on the table, in order to clean the pending list
- (5) Explicitly calling
gin_clean_pending_list(), instead of relying on Autovacuum - (6) Drop the GIN index
- If you have alternate ways of indexing the data, for example using expression indexes
Depending on your workload one or multiple of these approaches could be a good fit.
In addition, it’s important to ensure you have sufficient memory available during the GIN pending list cleanup. The memory limit used for the pending list flush can be confusing, and is not related to the size of gin_pending_list_limit. Instead it uses the following Postgres settings:
work_memduring regular INSERT/UPDATEmaintenance_work_memduringgin_clean_pending_list()callautovacuum_work_memduring autovacuum
Last but not least, you may want to consider partitioning or sharding a table that encounters problems like this. It may not be the easiest thing to do, but scaling GIN indexes to heavy write workloads is quite a tricky business.
GIN index support in the pganalyze Index Advisor
Not sure if your workload could utilize a GIN index, or which index to create for your queries?
We have now added initial support for GIN and GIST index recommendations to the pganalyze Index Advisor.
Here is an example of a GIN index recommendation for an existing tsvector column:
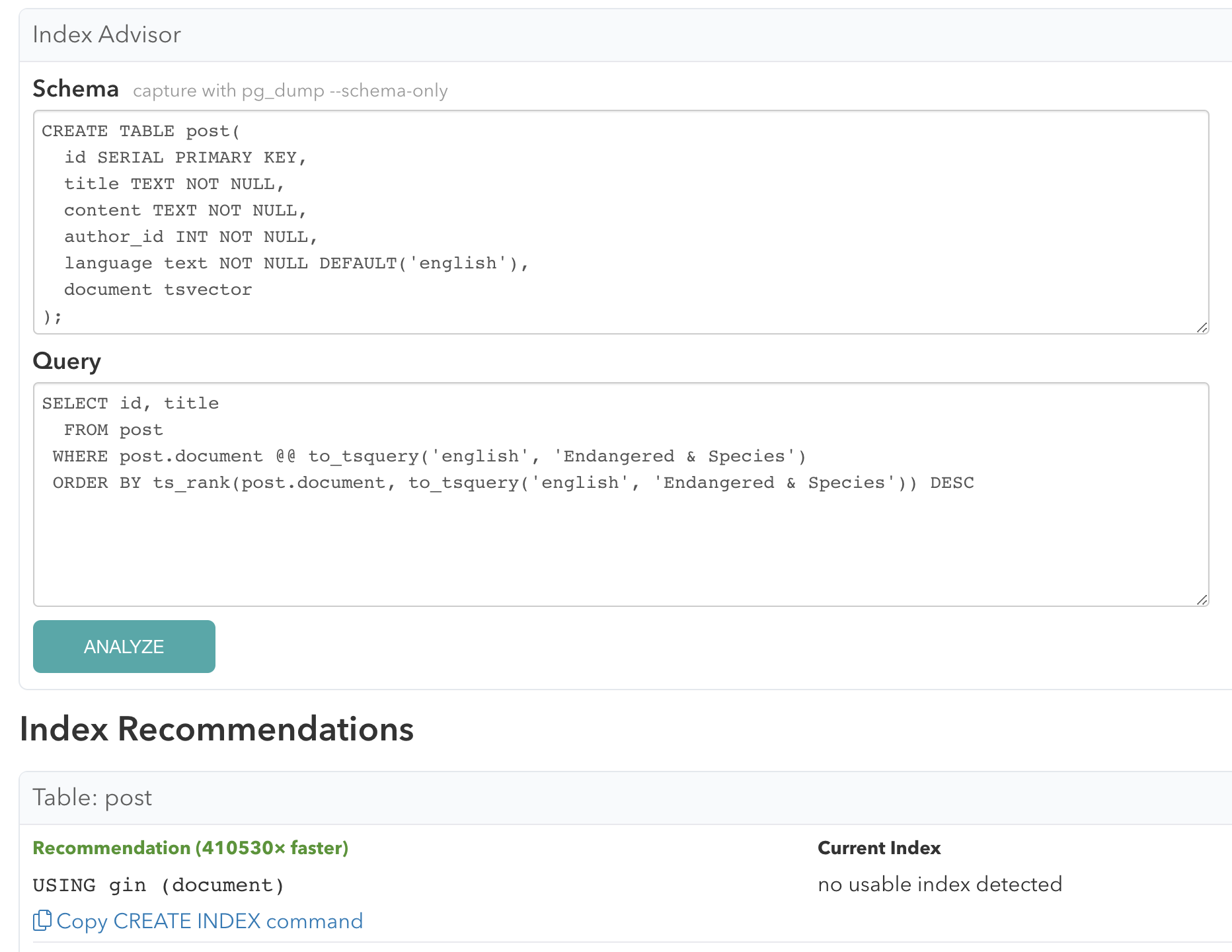
Note that the costing and size estimation logic for GIN and GIST indexes is still being actively developed.
We recommend trying out the Index Advisor recommendation on your own system to assess its effectiveness, as well as monitoring the production table for write overhead after you have added an index. You may also need to tweak your queries to make use of a particular index.
Conclusion
GIN indexes are powerful, and often the only way to index certain queries and data types. But with great power comes great responsibility. Use GIN indexes wisely, especially on tables that are heavily written to.
And when you are not sure which GIN index could work, try out the pganalyze Index Advisor.
If you want to share this article with your peers, feel free to tweet it.
Other helpful resources
Using Postgres CREATE INDEX: Understanding operator classes, index types & more
How we deconstructed the Postgres planner to find indexing opportunities
Efficient Search in Rails with Postgres (PDF eBook)
Efficient Postgres Full Text Search in Django
Full Text Search in Milliseconds with Rails and PostgreSQL
Efficient Pagination in Django and Postgres
eBook: Effective Indexing in Postgres
Webinar: How To Reason About Indexing Your Postgres Database