
Replacing Oracle Hints: Best Practices with pg_hint_plan on PostgreSQL
 By Lukas Fittl
By Lukas FittlIf you’re migrating from Oracle Database to PostgreSQL, you’re likely accustomed to using hints to optimize queries. In Oracle, these are special directives embedded in SQL (like /*+ INDEX(...) */) that steer the optimizer’s execution plan. They can be extremely useful but also introduce complexity and “hint debt” over time.
PostgreSQL takes a very different approach to query optimization. Rather than supporting built-in hints, the Postgres community, historically, has emphasized relying on its cost-based planner to choose execution plans based on statistics, indexes, and configuration parameters. In practice, that works many times, but there can be cases where the planner is stubborn and keeps picking a bad plan. In migration situations, this is particularly complicated, because performance may be dependent on a particular execution plan that was previously specified using an Oracle hint.
So you might ask yourself: how do you replicate or replace Oracle hints when you migrate to Postgres? That’s where the pg_hint_plan extension comes in.
In this post, we’ll explore the differences between Oracle’s hint system and PostgreSQL’s planner with pg_hint_plan, discuss when you still need hints in your Postgres queries, and walk through best practices for using pg_hint_plan effectively, including how pganalyze can help.
When (and when not) to use hints
It might be tempting to migrate all Oracle hints into pg_hint_plan, but this can be overkill and sometimes even counterproductive in PostgreSQL. Let’s talk about where hints fit into a well-tuned Postgres environment.
Relying on PostgreSQL’s cost-based planner
PostgreSQL is built around a cost-based planner that typically selects efficient execution paths without manual intervention. It uses:
- Statistics on table sizes, column data distribution, etc.
- Planner cost settings like
random_page_costandcpu_tuple_cost - Server configuration parameters such as
enable_seqscan,work_mem, andeffective_cache_size
The philosophy behind PostgreSQL’s planner is that if your statistics, indexes, and cost parameters are well-tuned, the engine can usually figure out the best plan on its own, and there is rarely a need to rely on hints.
However, this system isn’t perfect, and Postgres sometimes picks sub-optimal plans, as we’ve talked about in our Postgres planner quirks series.
Root causes of Postgres planner problems
A common problem with Postgres query plans are out of date, or incorrect statistics. Statistics about tables columns and the selectivity of query filters are critical for the planner to make good decisions. Frequent ANALYZE operations combined with tuned statistics target settings and using CREATE STATISTICS, ensure that the system captures current information about data distributions.
A thoughtfully designed schema with well-chosen indexes and, when appropriate, table partitioning, often provides a bigger performance boost than manual hints, which can only do so much on a large table.
Settings such as work_mem, random_page_cost, and effective_cache_size have a significant impact on the decisions the planner makes, yet they are often set at the default value, which can cause bad query plans. Optimizing these settings can resolve many query performance challenges without introducing hints. When the planner’s cost model aligns well with the realities of your hardware and data, it typically arrives at better plans.
When hints can help
Despite the strengths of PostgreSQL’s planner, there are times when hints prove beneficial. In fact, forcing a certain plan for debugging can offer valuable insight into why the planner’s default choice might be less than ideal, and which part of the query plan had inaccurate costs, often caused by statistics issues.
Legacy Oracle queries often rely heavily on hints, and adjusting them or restructuring the schema might be too risky or time-intensive. In such cases, pg_hint_plan can replicate specific behaviors from Oracle without a total rewrite. Hints also help in highly complex queries or unusual data distributions that consistently lead the planner astray. They are likewise useful as a temporary patch while deeper issues, such as missing statistics or incorrectly set parameters, are being addressed.
When statistical accuracy, schema design, and parameter tuning are all properly addressed in Postgres, hints become an added layer of complexity rather than a necessity. Use them sparingly, focusing on special cases that truly require hard-coded logic.
Mapping Oracle hints to pg_hint_plan
Both Oracle hints and pg_hint_plan hints are embedded in SQL statements using /*+ ... */. They can:
- Force the use of specific indexes or join methods (e.g., nested loops)
- Enable or disable parallel execution
- Override other plan choices
These hints can be very direct: “Use index X on this table,” or “Join table A and B using a Nested Loop Join.” This level of control is sometimes essential when the database optimizer doesn’t pick an optimal plan on its own or when you need consistent performance across different instances.
When you do decide to replicate Oracle hints in Postgres, you’ll likely look for direct equivalents. pg_hint_plan supports many—but not all—Oracle-like hints. pg_hint_plan primarily controls scan methods, join methods, join order, and query parallelism. Many of Oracle’s advanced hints for rewriting queries, star transformations, dynamic sampling, and specialized caching are simply not available or applicable in Postgres.
Instead, in Postgres, you often achieve similar behavior by tuning planner GUCs (like enable_hashjoin, enable_nestloop), rewriting queries, materializing parts of the query with the MATERIALIZED keyword for CTEs, or using indexes/constraints that nudge the Postgres planner.
Let’s review some common situations and map them from Oracle Database hints to pg_hint_plan syntax or other Postgres alternatives.
Access path (or index) hints
| Oracle Hint | pg_hint_plan Equivalent | Notes |
|---|---|---|
FULL(table)Force a full table scan | SeqScan(table) | Forces Postgres to use a sequential scan (called Full Table Scan on Oracle) on the named table. |
INDEX(table [index])Force index scan | IndexScan(table [index]) or IndexOnlyScan(table [index]) or BitmapScan(table [index]) | pg_hint_plan has separate hints for regular index scans, index-only scans, or bitmap index scans. |
INDEX_FFS(table index)Fast full index scan | No direct equivalent. IndexOnlyScan is approximate. | Postgres can answer a query from the index by using an IndexOnlyScan, if all filtered and returned columns are indexed. However, Postgres sometimes still checks the table to verify visibility of deleted rows (this cannot be turned off). |
INDEX_DESC(table [index])Reverse index scan | IndexScan with an ORDER BY … DESC in the query itself. | pg_hint_plan can’t directly enforce a descending index scan; you typically rely on query order or an index with the right sort order. |
NO_INDEX(table [index])Disallow index | No equivalent. | No equivalent to disallow individual indexes. |
INDEX_JOIN(table)Use index join | No equivalent. | PostgreSQL does not have a direct “index join” concept like Oracle. |
In Oracle, you might have:
SELECT /*+ INDEX(table1 idx_table1_col) */
col1, col2
FROM table1
WHERE col1 = 'something'
ORDER BY col2 LIMIT 1;
In PostgreSQL with pg_hint_plan, you’d translate it to:
/*+
IndexScan(table1 idx_table1_col)
*/
SELECT col1, col2
FROM table1
WHERE col1 = 'something'
ORDER BY col2 LIMIT 1;
Join operation hints
| Oracle Hint | pg_hint_plan Equivalent | Notes |
|---|---|---|
USE_NL(table1 table2)Use nested loops | NestLoop(table1 table2) | Forces a Nested Loop Join between the two named tables. |
USE_HASH(table1 table2)Use hash join | HashJoin(table1 table2) | Forces a Hash Join between the two named tables. |
USE_MERGE(table1 table2)Use sort-merge join | MergeJoin(table1 table2) | Forces a Merge Join between the two named tables. |
USE_NL_WITH_INDEX(t1 idx1) | NestLoop(table1 table2) + IndexScan(table1 index1) + Leading((table2 table1)) | In order to perform what Postgres calls a Parameterized Index Scan, the hints must force both a NestedLoop, the Join Order (via Leading) and the use of the correct Index. Note that the Leading hint requires use of extra parenthesis to force the ordering. The first table listed is the outer table, followed by the inner table (which is the one the index scan is on). |
NO_USE_NL(t1 [t2…])NO_USE_MERGE(t1 [t2…])NO_USE_HASH(t1 [t2…]) | NoNestLoop(t1 t2 [t3…])NoMergeJoin(t1 t2 [t3…])NoHashJoin(t1 t2 [t3…]) | pg_hint_plans instructs PostgreSQL’s query planner not to use a Nested Loop/Merge/Hash join for the listed tables (which need to include both the inner and the outer table), while the Oracle hint tells the optimizer not to use a Nested Loop/Merge/Hash join for each specified table where it is the inner table of the join. |
Join order hints
| Oracle Hint | pg_hint_plan Equivalent | Notes |
|---|---|---|
ORDEREDJoin in the order of tables in the FROM clause | Set(join_collapse_limit 1) | In Postgres, setting the join_collapse_limit setting to “1” will force Postgres to join the tables in the order they are listed in the query. You can set this either via pg_hint_plan or a regular SET command before running the query. See examples in the Postgres documentation. |
LEADING(t1 t2 … tN) | Leading(t1 t2 … tN)Leading(((t1 t2) t3)) | pg_hint_plan supports Leading(…) to fix the join order. You can list multiple tables in the desired join sequence. Use the syntax with additional parenthesis around each pair to specify which table is used as the inner vs outer table. |
Parallel / degree of parallelism hints
| Oracle Hint | pg_hint_plan Equivalent | Notes |
|---|---|---|
PARALLEL(table, n)Parallel degree n | Parallel(table n hard) | pg_hint_plan by default (“soft”) only sets the configured maximum number of workers (max_parallel_workers_per_gather) but won’t force a parallel plan if the costs are not in its favor. You can force a parallel plan by specifying the third argument as hard, which matches Oracle’s behaviour when specifying a specific parallel degree. |
NO_PARALLEL(table)Disallow parallel | Parallel(table 0) | pg_hint_plan inhibits parallel execution when the table value is set to zero. |
Example usage in pg_hint_plan, increasing the parallel workers from the default of 2 (max_parallel_workers_per_gather) to 4 just for this query’s use of the “sales” table:
/*+
Parallel(sales 4)
*/
SELECT ...
Query transformation & subquery hints
Oracle has many hints controlling query transformations (like unnesting subqueries, merging views, star transformations, etc.). pg_hint_plan does not provide direct equivalents for these transformations; PostgreSQL’s planner transformations are generally not hint-based but either controlled automatically or by GUC parameters.
| Oracle Hint | pg_hint_plan Equivalent | Notes |
|---|---|---|
UNNEST / NO_UNNEST | None | PostgreSQL decides automatically on subquery unnesting (lateral joins, subquery flattening, etc.), and pg_hint_plan cannot influence this. However, queries can be rewritten to use a CTE with the NOT MATERIALIZED keyword, which will behave similar to Oracle’s UNNEST, or MATERIALIZED which will behave like NO_UNNEST. See Postgres documentation. |
MERGE / NO_MERGE | None | In Postgres, views are inlined automatically as if they were a subquery; there is no fine-grained hint for controlling this. |
PUSH_SUBQ / NO_PUSH_SUBQ | None | No direct control over subquery execution in pg_hint_plan. |
STAR_TRANSFORMATION / NO_STAR_TRANSFORMATION | None | Oracle’s star transformations for data warehouse schemas have no direct counterpart in Postgres. |
FACT / NO_FACT | None | Oracle uses these for star schemas; not applicable in Postgres. |
Result cache and other specialized hints
| Oracle Hint | pg_hint_plan Equivalent | Notes |
|---|---|---|
RESULT_CACHE / NO_RESULT_CACHE | None | PostgreSQL does not have a built-in query result cache like Oracle. |
OPT_PARAM(…) | Set(…) | Postgres parameters are typically set at the session level (“SET” command) or via “Set” hints in pg_hint_plan. Note the parameters that can be set differ between Oracle and Postgres. |
DYNAMIC_SAMPLING(…) | None | Postgres statistics system works based on a separate ANALYZE of the table outside of query execution and does not have an equivalent of dynamic sampling. |
QB_NAME | None | pg_hint_plan does not offer an equivalent to Oracle’s query block functionality for hints. |
PUSH_PRED / NO_PUSH_PRED | None | Postgres handles predicate pushdown automatically based on heuristics for subqueries; no direct hint. |
USE_CONCAT | None | Oracle uses this to force expansion of OR clauses into UNION ALL queries. Postgres does not support doing this transformation automatically, manual rewrite of the query is needed. See our blog post for an example. |
NO_QUERY_TRANSFORMATION | None | Postgres’s transformations during the planning process can not be turned off / modified via hints. |
Additional pg_hint_plan Features (no Oracle equivalent)
pg_hint_plan has additional hints that don’t map to Oracle hints but can be helpful:
Rows(table1 table2 [ n ]): Tells the planner to assume a join betweentable1 and table 2returnsnrows (replacing or adjusting the statistics-derived estimate), influencing join order and plan choices.Memoize(table1 table2)/NoMemoize(table1 table2): Influences whether the Memoize functionality is applied to the given join tables. Memoize can sometimes cause Postgres planner costs to be off, and as such the “NoMemoize” hint can be useful to avoid query plans that might favor a Nested Loop Join.
Best practices for debugging pg_hint_plan hints
Sometimes a pg_hint_plan hint won’t take effect, and it’s not always clear why that might be, as Postgres will always give you a plan, even if the pg_hint_plan hints did not take effect.
The most common problems can be:
- Specifying multiple hint comments (if you have multiple hints you must specify them all in one
/*+ ... */comment) - Using incorrect pg_hint_plan syntax (e.g.
NestedLoopinstead ofNestLoop) - The planner not having a viable path to use the hint (e.g. because the requested index can’t be used for a given expression)
- Re-used table names not having unique aliases in a query (you need to assign an alias to each table in such situations)
- Hints for partitioned tables must target the partition table parent, not the children
- Subqueries that do not have an assigned name (i.e. are not a CTE) can only be hinted in some cases
However, by default you may not see any clear indication of a problem, since pg_hint_plan does not show any debug output by default.
To understand better why hints may not have been used, you can enable the pg_hint_plan.print_debug flag. This will give you output like this:
SET pg_hint_plan.debug_print = true;
/*+ NestedLoop(table1 table2) */ EXPLAIN SELECT * FROM …;
INFO: pg_hint_plan: hint syntax error at or near "NestedLoop".
DETAIL: Unrecognized hint keyword "NestedLoop".
QUERY PLAN
----------------------------------------------------------------------------------------------------
…
Additionally you can show more detailed output about hint usage by raising the client log level (client_min_messages) to LOG, which will tell you which hints were used successfully:
SET client_min_messages = LOG;
/*+ NestLoop(table1 table2) IndexScan(table3) */ EXPLAIN SELECT * FROM table1 JOIN table2
ON (table2_id = table2.id) WHERE table1_id = '123';
LOG: pg_hint_plan:
used hint:
NestLoop(table1 table2)
not used hint:
IndexScan(table3)
duplication hint:
error hint:
QUERY PLAN
----------------------------------------------------------------------------------------------
...
You can find additional aspects to consider in the pg_hint_plan documentation.
Using pganalyze to test query hints
Oftentimes Oracle-to-Postgres migrations run into challenges when on a deadline to complete pre-production performance testing or right after going live. In such situations, pganalyze can help you quickly iterate on different hints and benchmark query plans using Query Tuning Workbooks.
In the following example, we compared a baseline query with a query variant that uses pg_hint_plan to choose a particular index. From these results, it’s clear that implementing the hint improves performance by more than 60%, plus it’s documented for the whole team to see why the change was made.
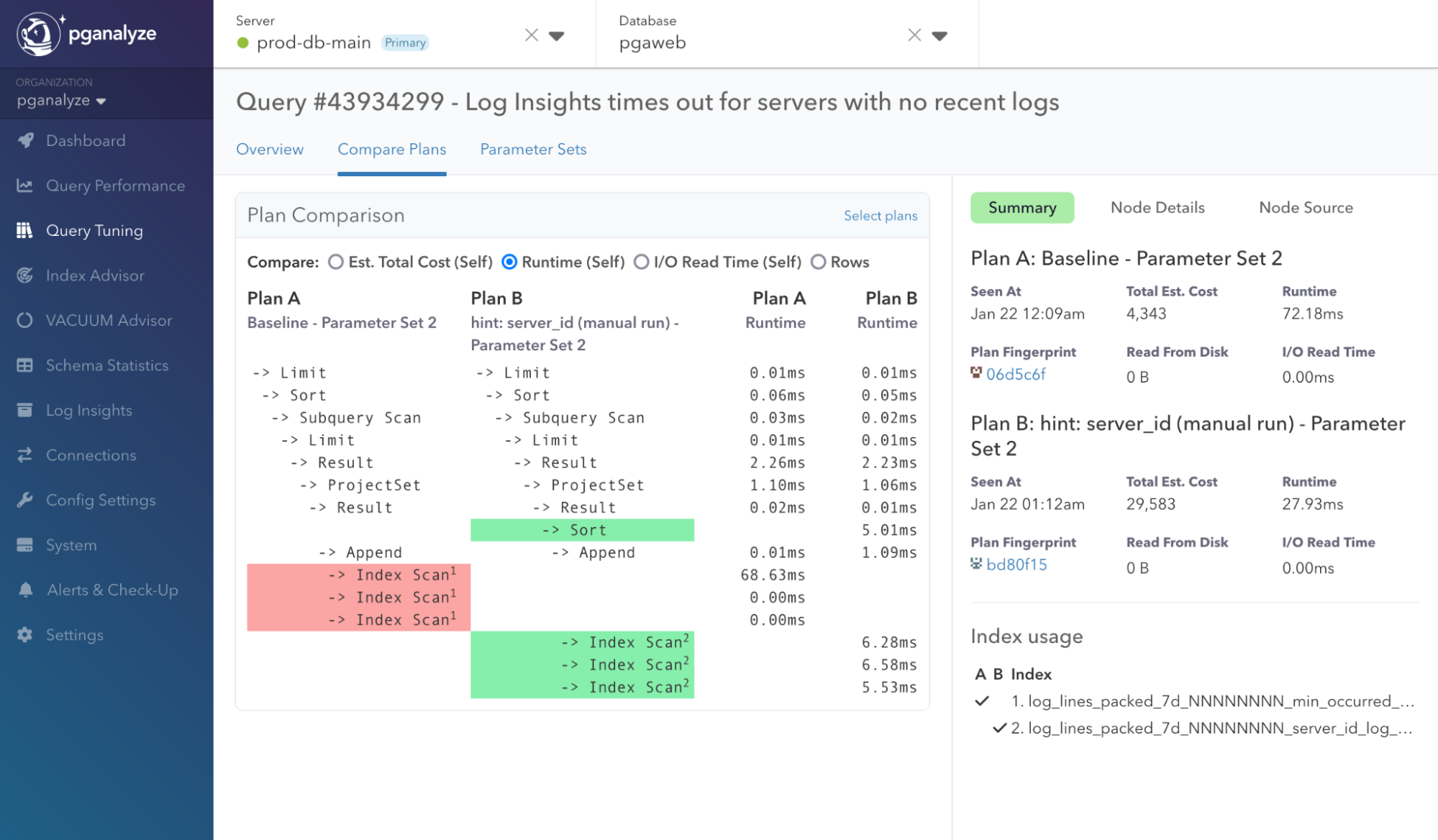
By iterating through this process of identifying slow queries, testing variants, and implementing optimizations, you avoid guesswork, ensure that each hint actually benefits your application, and prevent adding unnecessary complexity to your database.
Conclusion
Migrating Oracle hints to PostgreSQL can be a tricky process, but pg_hint_plan provides a valuable tool for those times when you really need to guide Postgres’ planner. Nonetheless, remember that PostgreSQL is intended to make sound decisions based on strong statistics, strategic indexing, and well-chosen cost parameters, which can all be optimized using pganalyze. Hints should serve as a targeted solution, not the default approach.
References
Documentation
- pg_hint_plan GitHub Repository
- pg_hint_plan Documentation
- Oracle Database - Hint documentation
- pganalyze Query Tuning Workbooks
- PostgreSQL Documentation: 17: 14.3. Controlling the Planner with Explicit JOIN Clauses
- PostgreSQL Documentation: 17: 7.8. WITH Queries (Common Table Expressions)
5mins of Postgres episodes on planner quirks
- JOIN Equivalence Classes and IN/ANY filters
- How to fix bad JSONB selectivity estimates
- The impact of ORDER BY + LIMIT on index usage
Webinars & eBooks
- How to Optimize Slow Queries with EXPLAIN to Fix Bad Query Plans
- Best Practices for Optimizing Postgres Query Performance
Blog posts
- The surprising logic of the Postgres work_mem setting, and how to tune it
- Introducing pganalyze Index Advisor 3.0 - A workload-aware system for finding missing indexes in Postgres
- How Postgres Chooses Which Index To Use For A Query
- Speed up Postgres queries with UNIONs and subquery pull-up
- Introducing Query Tuning Workbooks: Safely Tune Postgres Queries on Production with pganalyze